Servidor Web
Los servidores web son uno de los aspectos más importantes de Internet, ya que se trata de los encargados de despachar las páginas a los usuarios. Sin ellos, Internet como lo conocemos hoy en día simplemente no sería posible. Hoy veremos a fondo varios de los detalles más interesantes de los servidores web y su funcionamiento.
¿Qué es un servidor web?
Quienes tengan conocimientos sobre lo que es un servidor no deben confundirlo con un servidor web, porque son dos cosas distintas, aunque sí es cierto que uno forma parte del otro, ya que de hecho el servidor web es uno de los componentes de un servidor. El server (o servidor) es el equipo en el cual se alojan los sitios o aplicaciones web, mientras que el servidor web es un software que forma parte del servidor.
El servidor web (también llamado webserver en inglés) es el software que se encarga de despachar el contenido de un sitio web al usuario.
Este proceso de despacho, que a simple vista parece muy simple, es en realidad más complejo de lo que parece, pues toda la «magia» de un webserver ocurre fuera de quien está navegando por un sitio web. Existen multitud de servidores web, y entre los más conocidos podemos encontrar por ejemplo a Apache, Nginx, LiteSpeed o IIS.
Los servidores web varían mucho de uno a otro, por ejemplo si comparamos Apache y Nginxveremos que tienen diferencias muy notorias, aunque el objetivo final es el mismo: despachar contenido al usuario.
El proceso de despacho comienza en nuestro navegador web. Al escribir la dirección de un sitio web y presionar enter comienza la siguiente secuencia: el sistema hace una búsqueda DNS para encontrar en cuál servidor está alojado el sitio en cuestión.
Cuando el server es encontrado, el navegador le pide el contenido del sitio web, y acto seguido el webserver procesa este pedido y envía dicho contenido al navegador, lo cual da como resultado la visualización del sitio en nuestra pantalla.
Tomcat
Tomcat es un contenedor de Servlets con un entorno JSP. Un contenedor de Servlets es un shell de ejecución que maneja e invoca servlets por cuenta del usuario.
Podemos dividir los contenedores de Servlets en:
- Contenedores de Servlets Stand-alone (Independientes)
Estos son una parte integral del servidor web. Este es el caso cuando usando un servidor web basado en Java, por ejemplo, el contenedor de servlets es parte de JavaWebServer (actualmente sustituido por iPlanet). Este el modo por defecto usado por Tomcat.
Sin embargo, la mayoría de los servidores, no están basados en Java, los que nos lleva los dos siguientes tipos de contenedores: - Contenedores de Servlets dentro-de-Proceso
El contenedor Servlet es una combinación de un plugin para el servidor web y una implementación de contenedor Java. El plugind del servidor web abre una JVM (Máquina Virtual Java) dentro del espacio de direcciones del servidor web y permite que el contenedor Java se ejecute en él. Si una cierta petición debería ejecutar un servlet, el plugin toma el control sobre la petición y lo pasa al contenedor Java (usando JNI). Un contenedor de este tipo es adecuado para servidores multi-thread de un sólo proceso y proporciona un buen rendimiento pero está limitado en escalabilidad - Contenedores de Servlets fuera-de-proceso
El contenedor Servlet es una combinación de un plugin para el servidor web y una implementación de contenedor Java que se ejecuta en una JVM fuera del servidor web. El plugin del servidor web y el JVM del contenedor Java se comunican usando algún mecanismo IPC (normalmente sockets TCP/IP). Si una cierta petición debería ejecutar un servlet, el plugin toma el control sobre la petición y lo pasa al contenedor Java (usando IPCs). El tiempo de respuesta en este tipo de contenedores no es tan bueno como el anterior, pero obtiene mejores rendimientos en otras cosas (escalabilidad, estabilidad, etc.).
Tomcat puede utilizarse como un contenedor solitario (principalmente para desarrollo y depuración) o como plugin para un servidor web existente (actualmente se soporan los servidores Apache, IIS y Netscape). Esto significa que siempre que despleguemos Tomcat tendremos que decidir cómo usarlo, y, si seleccionamos las opciones 2 o 3, también necesitaremos instalar un adaptador de servidor web
GlassFish
GlassFish es una Comunidad y un proyecto de Servidor de Aplicaciones que fue iniciado por Sun Microsystems para la plataforma Java EE y por un tiempo fue patrocinado por Oracle Corporation. La versión comercial es denominada Oracle GlassFish Enterprise Server (antes Sun GlassFish Enterprise Server). GlassFish es un software libre, con una doble licencia bajo la sombrilla de dos de las licencias del software libre: Common Development and Distribution License (CDDL) y GNU General Public License (GPL) with the classpath exception.
GlassFish está basado en el código fuente donado por Sun y Oracle Corporation; este último proporcionó el módulo de persistencia TopLink(http://www.oracle.com/technology/products/ias/toplink/index.html). GlassFish tiene como base al servidor Sun Java System Application Server de Oracle Corporation, un derivado de Apache Tomcat, y que usa un componente adicional llamado Grizzly que usa Java NIO para escalabilidad y velocidad. Oracle GlassFish Server, la versión del producto, y Oracle GlassFish Server Open Source edition, la versión de código abierto, son referidos como el servidor GlassFish.
Otros servidores web para Java
Apache Geronimo
Oracle WebLogic
SAP NetWeaver
WildFly
Arquitectura Cliente Servidor
Arquitectura Cliente servidor. Esta arquitectura consiste básicamente en un cliente que realiza peticiones a otro programa (el servidor) que le da respuesta. Aunque esta idea se puede aplicar a programas que se ejecutan sobre una sola computadora es más ventajosa en un sistema operativo multiusuario distribuido a través de una red de computadoras. La interacción cliente-servidor es el soporte de la mayor parte de la comunicación por redes. Ayuda a comprender las bases sobre las que están construidos los algoritmos distribuidos.
Partes que componen el sistema
Cliente: Programa ejecutable que participa activamente en el establecimiento de las conexiones. Envía una petición al servidor y se queda esperando por una respuesta. Su tiempo de vida es finito una vez que son servidas sus solicitudes, termina el trabajo.
Servidor: Es un programa que ofrece un servicio que se puede obtener en una red. Acepta la petición desde la red, realiza el servicio y devuelve el resultado al solicitante. Al ser posible implantarlo como aplicaciones de programas, puede ejecutarse en cualquier sistema donde exista TCP/IP y junto con otros programas de aplicación. El servidor comienza su ejecución antes de comenzar la interacción con el cliente. Su tiempo de vida o de interacción es “interminable”.
Los servidores pueden ejecutar tareas sencillas (caso del servidor hora día que devuelve una respuesta) o complejas (caso del servidor ftp en el cual se deben realizar operaciones antes de devolver una respuesta). Los servidores sencillos procesan una petición a la vez (son secuenciales o interactivos), por lo que no revisan si ha llegado otra petición antes de enviar la respuesta de la anterior.
Los servidores pueden ejecutar tareas sencillas (caso del servidor hora día que devuelve una respuesta) o complejas (caso del servidor ftp en el cual se deben realizar operaciones antes de devolver una respuesta). Los servidores sencillos procesan una petición a la vez (son secuenciales o interactivos), por lo que no revisan si ha llegado otra petición antes de enviar la respuesta de la anterior.
Los más complejos trabajan con peticiones concurrentes aún cuando una sola petición lleve mucho tiempo para ser servida (caso del servidor ftp que debe copiar un archivo en otra máquina). Son complejos pues tienen altos requerimientos de protección y autorización. Pueden leer archivos del sistema, mantenerse en línea y acceder a datos protegidos y a archivos de usuarios. No puede cumplir a ciegas las peticiones de los clientes, deben reforzar el acceso al sistema y las políticas de protección. Los servidores por lo general tienen dos partes:
- Programa o proceso que es responsable de aceptar nuevas peticiones: Maestro o Padre.
- Programas o procesos que deben manejar las peticiones individuales: Esclavos o Hijos.
Tareas del programa maestro
- Abrir un puerto local bien conocido al cual pueda acceder los clientes.
- Esperar las peticiones de los clientes.
- Elegir un puerto local para las peticiones que llegan en informar al cliente del nuevo puerto, (innecesario en la mayoría de los casos).
- Iniciar un programa esclavo o proceso hijo que atienda la petición en el puerto local, (el esclavo cuando termina de manejar una petición no se queda esperando por otras).
- Volver a la espera de peticiones mientras los esclavos, en forma concurrente, se ocupan de las anteriores peticiones.
Características de la arquitectura Cliente-Servidor
- Combinación de un cliente que interactúa con el usuario, y un servidor que interactúa con los recursos a compartir. El proceso del cliente proporciona la interfaz entre el usuario y el resto del sistema. El proceso del servidor actúa como un motor de software que maneja recursos compartidos tales como bases de datos, impresoras, Módem, etc.
- Las tareas del cliente y del servidor tienen diferentes requerimientos en cuanto a recursos de cómputo como velocidad del procesador, memoria, velocidad y capacidades del disco e input-output devices.
- Se establece una relación entre procesos distintos, los cuales pueden ser ejecutados en la misma máquina o en máquinas diferentes distribuidas a lo largo de la red.
- Existe una clara distinción de funciones basadas en el concepto de”servicio”, que se establece entre clientes y servidores.
- La relación establecida puede ser de muchos a uno, en la que un servidor puede dar servicio a muchos clientes, regulando su acceso a los recursos compartidos.
- Los clientes corresponden a procesos activos en cuanto a que son estos los que hacen peticiones de servicios. Estos últimos tienen un carácter pasivo, ya que esperan peticiones de los clientes.
- No existe otra relación entre clientes y servidores que no sea la que se establece a través del intercambio de mensajes entre ambos. El mensaje es el mecanismo para la petición y entrega de solicitudes de servicios.
- El ambiente es heterogéneo. La plataforma de hardware y el sistema operativo del cliente y del servidor no son siempre los mismos. Precisamente una de las principales ventajas de esta arquitectura es la posibilidad de conectar clientes y servidores independientemente de sus plataformas.
- El concepto de escalabilidad tanto horizontal como vertical es aplicable a cualquier sistema Cliente-Servidor. La escalabilidad horizontal permite agregar más estaciones de trabajo activas sin afectar significativamente el rendimiento. La escalabilidad vertical permite mejorar las características del servidor o agregar múltiples servidores.
Ventajas del esquema Cliente-Servidor
Existencia de plataformas de hardware cada vez más baratas. Esta constituye a su vez una de las más palpables ventajas de este esquema, la posibilidad de utilizar máquinas mucho más baratas que las requeridas por una solución centralizada, basada en sistemas grandes (mainframes). Además, se pueden utilizar componentes, tanto de hardware como de software, de varios fabricantes, lo cual contribuye considerablemente a la reducción de costos y favorece la flexibilidad en la implantación y actualización de soluciones.
- Facilita la integración entre sistemas diferentes y comparte información, permitiendo por ejemplo que las máquinas ya existentes puedan ser utilizadas pero utilizando interfaces más amigables el usuario. De esta manera, se puede integrar PCs con sistemas medianos y grandes, sin necesidad de que todos tengan que utilizar el mismo sistema operativo.
- Al favorecer el uso de interfaces gráficas interactivas, los sistemas construidos bajo este esquema tienen una mayor y más intuitiva con el usuario. En el uso de interfaces gráficas para el usuario, presenta la ventaja, con respecto a uno centralizado, de que no siempre es necesario transmitir información gráfica por la red pues esta puede residir en el cliente, lo cual permite aprovechar mejor el ancho de banda de la red.
- La estructura inherentemente modular facilita además la integración de nuevas tecnologías y el crecimiento de la infraestructura computacional, favoreciendo así la escalabilidad de las soluciones.
- Contribuye además a proporcionar a los diferentes departamentos de una organización, soluciones locales, pero permitiendo la integración de la información.
Desventajas
- El mantenimiento de los sistemas es más difícil pues implica la interacción de diferentes partes de hardware y de software, distribuidas por distintos proveedores, lo cual dificulta el diagnóstico de fallas.
- Cuenta con muy escasas herramientas para la administración y ajuste del desempeño de los sistemas.
- Es importante que los clientes y los servidores utilicen el mismo mecanismo (por ejemplo sockets o RPC), lo cual implica que se deben tener mecanismos generales que existan en diferentes plataformas.
- Hay que tener estrategias para el manejo de errores y para mantener la consistencia de los datos.
- El desempeño (performance), problemas de este estilo pueden presentarse por congestión en la red, dificultad de tráfico de datos, etc.
Tipos de datos en Java
Todo lenguaje de programación consta de elementos específicos que permiten realizar las operaciones básicas de la programación: tipos de datos, operadores e instrucciones o sentencias. En este apartado se introducen los distintos tipos de dato que pueden emplearse en la programación con Java.

VARIABLE
Una variable es un espacio de la memoria correspondiente a un dato cuyo valor puede modificarse durante la ejecución de un programa y que está asociado a un identificador. Toda variable ha de declararse antes de ser usada en el código de un programa en Java. En la declaración de una variable debe indicarse explícitamente el identificador de la variable y el tipo de dato asociado. El tipo de dato determina el espacio reservado en memoria, los diferentes valores que puede tomar la variable y las operaciones que pueden realizarse con ella. La declaración de una variable en el código fuente de un programa de Java puede hacerse de la siguiente forma:
tipo_de_dato identificador_de_la_variable;
O bien, la declaración de múltiples variables (con los correspondientes identificadores separados por comas) del mismo tipo:
tipo_de_dato ident_1, ident_2, . . . , ident_n;
Por ejemplo:
int n; double x, y;VARIABLES FINAL O CONSTANTES
Las variables finales en Java son similares a las constantes empleadas en otros lenguajes de programación. Una vez inicializada una variable final su valor no puede ser modificado. La declaración de variables finales o constantes se realiza empleando la palabra reservada
final antes del identificador del tipo de dato. Por ejemplo:final int MAXIMO = 15;
Identificador
Los identificadores son los nombres que el programador asigna a variables, constantes, clases, métodos, paquetes, etc. de un programa.
Características de un identificador Java:
- Están formados por letras y dígitos.
- No pueden empezar por un dígito.
- No pueden contener ninguno de los caracteres especiales.
- No puede ser una palabra reservada de Java.
Comentarios
Cuando escribimos código en general es útil realizar comentarios explicativos. Los comentarios no tienen efecto como instrucciones para el ordenador, simplemente sirven para que cuando un programador lea el código pueda comprender mejor lo que lee.
- Comentario multilínea: se abre con el símbolo /* y se cierra con el símbolo */
- Comentario en una línea o al final de una línea: se introduce con el símbolo //
/*
* Este es el primer programa en un IDE del curso Java
* Creado el 29/03/2017
* aprenderaprogramar.com
*/
// A continuación el código del programa
public class Ejemplo {
public static void main(String[ ] arg) {
System.out.println("Hola Java"); //Usamos esta sintaxis para mostrar mensajes por pantalla
}
}
|
Operadores:
Operador Asignación
El operador asignación =, es un operador binario que asigna el valor del término de la derecha al operando de la izquierda. El operando de la izquierda suele ser el identificador de una variable. El término de la derecha es, en general, una expresión de un tipo de dato compatible; en particular puede ser una constante u otra variable. Como caso particular, y a diferencia de los demás operadores, este operador no se evalúa devolviendo un determinado valor.

Operadores Aritméticos
El lenguaje de programación Java tiene varios operadores aritméticos para los datos numéricos enteros y reales. En la siguiente tabla se resumen los diferentes operadores de esta categoría.

Operadores Aritméticos Incrementales
Los operadores aritméticos incrementales son operadores unarios (un único operando). El operando puede ser numérico o de tipo char y el resultado es del mismo tipo que el operando. Estos operadores pueden emplearse de dos formas dependiendo de su posición con respecto al operando.

Operadores Aritméticos Combinados
Combinan un operador aritmético con el operador asignación. Como en el caso de los operadores aritméticos pueden tener operandos numéricos enteros o reales y el tipo específico de resultado numérico dependerá del tipo de éstos. En la siguiente tabla se resumen los diferentes operadores de esta categoría.

Operadores de Relación
Realizan comparaciones entre datos compatibles de tipos primitivos (numéricos, carácter y booleanos) teniendo siempre un resultado booleano. Los operandos booleanos sólo pueden emplear los operadores de igualdad y desigualdad.

Operadores Lógicos o Booleanos
Realizan operaciones sobre datos booleanos y tienen como resultado un valor booleano. En la siguiente tabla se resumen los diferentes operadores de esta categoría.

Prioridad entre Operadores
Si dos operadores se encuentran en la misma expresión, el orden en el que se evalúan puede determinar el valor de la expresión. En la siguiente tabla se muestra el orden o prioridad en el que se ejecutan los operadores que se encuentren en la misma sentencia. Los operadores de la misma prioridad se evalúan de izquierda a derecha dentro de la expresión

Manejo De Fechas En Java
1. Las clases java.util.Date y java.sql.Date. Son dos de las clases más usadas cuando una aplicación implica el trabajo con fechas:
java.util.Date: Según la documentación "La clase java.util.Date representa un instante de tiempo específico, con precisión de milisegundos"; esto más que ser una especie de "autoadulación" para la clase, quiere decir que no solo se trata de una simple cadena al estilo yyyy/MM/dd, sino que almacena hasta milisegundos y que es posible trabajar con ellos.
Antes del jdk1.1 la clase java.util.Date tenía dos funciones adicionales a la que conocemos ahora, una de ellas era la interpretación de datos que tenían que ver con fechas, como años, días, segundos, entre otros. La otra era el formateo (la forma como se muestra) y parseo (convertir un String a java.util.Date). Pero debido a las dificultades que presentaban estas funcionalidades a la hora de internacionalizar los programas, esos métodos ya está obsoletos y la clase java.util.Calendar se encargó de esto; así que en este momento esta clase, sólo hace lo que se mencionó al principio: "representa un instante de tiempo específico, con precisión de milisegundos"; más adelante veremos como ampliar esta funcionalidad. Por ahora veamos las convenciones que sigue esta clase:
* El año "y" está representado por un entero igual a ("y" - 1900). Por ejemplo el año 2004 se representa como 104 (2004 - 1900).
* Los meses son representados por números entre 0 y 11, donde enero es 0 y diciembre es 11.
* Los días y minutos se representan de forma corriente. Entre 1 - 31 y 0 - 59 respectivamente.
* Las horas van entre 0 y 23, donde la medianoche es 0 y el medio día 12.
* Los segundos van entre 0 y 61. 61 solo ocurre cuando se agrega el segundo adicional para ajustar la diferencia entre el reloj atómico y el tiempo de rotación de la tierra.
No sobra mencionar que los métodos para obtener el año, mes y día de esta clase ya están obsoletos y lo único que hacen es llamar a la clase java.util.Calendar para que esta se encargue de hacerlo (una delegación).
java.sql.Date: Esta clase hereda de java.util.Date y es la representación de la fecha cuando trabajamos con JDBC (Java DabaBase Connectivity), es decir, son los campos almacenados en una base de datos cuyo tipo es una fecha que puede o no incluir la hora, aunque la clase java.sql.Date siempre lo hace. Al igual que su clase padre, tiene una precisión de milisegundos, con la excepción que al mostrarla en la salida estándar con el formato por defecto solo muestra el día, mes y año. Hay que anotar también que para campos que almacenen solamente horas existen otras clases para manejarlos.
En resumen ambas clases, sólo se encargan de almacenar la cantidad de milisegundos que han pasado desde las 12 de la noche del primero de enero de 1970 en el meridiano de Greenwich. Aquí vienen dos puntos importantes:
a) Si la fecha que almacena cualquiera de las clases es menor a las 00:00:00 enero 1 de 1970 GMT, su valor el milisegundos será negativo.
b) La fecha es susceptible a la zona horaria. Por ejemplo en Colombia los milisegundos no se empiezan a contar desde enero 1 de 1970, sino a partir de las 19:00 de diciembre 31 de 1969. Esto es importante por que si transportamos una fecha relativa de una zona a otra, podemos llegar a tener problemas al confiar en los milisegundos que se tienen; además como la clase intenta representar el "Tiempo Universal Coordinado" (UTC) suma 0.9 segundos cada año para ajustar la diferencia entre el reloj atómico y la velocidad de rotación de la tierra. Esto se traduce en que muy dificilmente podemos basarnos en valores como 0 o 60000 para realizar validaciones, pues esos milisegundos no son controlables cuando creamos la instancia de una fecha, peor aún, los milisegundos no son ni siquiera iguales para la misma fecha en la misma zona horaria.
Ambas clases se pueden instanciar directamente mediante new(), pero la clase java.sql.Date necesita un parámetro en el constructor: el tiempo en milisegundos, así que las siguientes instrucciones son válidas:
java.util.Date fechaActual = new java.util.Date(); //Fecha actual del sistema
java.sql.Date inicioLocal = new java.sql.Date(0); //Milisegundo cero
//también se puede crear una instancia de java.util.Date con parámetros iniciales
java.util.Date otraFecha = new java.util.Date(1000); //El primer segundo a partir del inicio
Prueba a imprimir cada uno de estos valores y fíjate en la diferencia de formatos entre java.sql.Date y java.util.Date. Se puede pasar de java.sql.Date a java.util.Date de dos fomas, una de ellas es con una asignación simple:
java.util.Date utilDate = null;
java.sql.Date sqlDate = new java.sql.Date(0);
utilDate = sqlDate;
/* aunque es java.util.Date,
si la imprimes tendrá el formato de java.sql.Date, recordemos que java.sql.Date hereda de
java.util.Date */
System.out.println(utilDate);
También se pueden tomar los milisegundos de java.sql.Date y pasarlos al constructor de java.util.Date:
java.util.Date utilDate = null;
java.sql.Date sqlDate = new java.sql.Date(0);
utilDate = new java.util.Date(sqlDate.getTime());
//esta vez se mostrará con el formato de java.util.Date
System.out.println(utilDate);
Para pasar de java.util.Date a java.sql.Date se deben tomar los milisegundos de la primera y pasarlos al constructor de la segunda:
java.util.Date utilDate = new java.util.Date();
java.sql.Date sqlDate = new java.sql.Date(utilDate.getTime());
//Con formato de java.sql.Date
System.out.println(sqlDate);
Para comparar fechas usamos el método compareTo() que internamente compara los milisegundos entre ellas usando directamente los métodos getTime() de ambas clases.
java.util.Date utilDate = new java.util.Date();
java.sql.Date sqlDate = new java.sql.Date(utilDate.getTime());
if (utilDate.compareTo(sqlDate) == 0){
System.out.println("IGUALES");
}else{
System.out.println("DIFERENTES");
}
O lo que es equivalente:
java.util.Date utilDate = new java.util.Date();
java.sql.Date sqlDate = new java.sql.Date(utilDate.getTime());
if (utilDate.getTime() == sqlDate.getTime()){
System.out.println("IGUALES");
}else{
System.out.println("DIFERENTES");
}
2. Las clases Time y Timestamp.
Ambas clases pertenecen al API JDBC y son la encargadas de representar los campos de estos tipos en una base de datos. Esto no quiere decir que no se puedan usar con otros fines. Al igual que java.sql.Date, son hijas (heredan) de java.util.Date, es decir, su núcleo son los milisegundos.
La clase Time es un envoltorio de la clase java.util.Date para representar los datos que consisten de horas, minutos, segundos y milisegundos, mientras Timestamp representa estos mísmos datos más un atributo con nanosegundos, de acuerdo a las especificaciones del lenguaje SQL para campos de tipo TIMESTAMP.
Como ambas clases heredan del java.util.Date, es muy fácil pasar de un tipo de dato a otro; similar a la clase java.sql.Date, tanto Time como Timestamp se pueden instanciar directamente y su constructor tiene como parámetro el número de milisegundos; como es de imaginarse, cuando se muestra alguna de las clases mediante su método toString() se ven los datos que intentan representar; La clase Time sólamente muestra la hora, minutos y segundo, mientras timestamp agrega fracciones de segundo a la cadena.
Para convertir entre tipos de datos diferentes debemos usar los milisegundos de una clase y asignarlos a las instancias de las otras, y como la clase java.util.Date es superclase de todas, a una instancia de esta podemos asignar cualquiera de las otras, manteniendo los métodos de la clase asignada, es decir, si asignamos un Time a una java.util.Date, al imprimir se verá el mismo formato de la clase Time.
Con este código:
java.util.Date utilDate = new java.util.Date(); //fecha actual
long lnMilisegundos = utilDate.getTime();
java.sql.Date sqlDate = new java.sql.Date(lnMilisegundos);
java.sql.Time sqlTime = new java.sql.Time(lnMilisegundos);
java.sql.Timestamp sqlTimestamp = new java.sql.Timestamp(lnMilisegundos);
System.out.println("util.Date: "+utilDate);
System.out.println("sql.Date: "+sqlDate);
System.out.println("sql.Time: "+sqlTime);
System.out.println("sql.Timestamp: "+sqlTimestamp);
Se obtiene la siguiente salida:
util.Date: Thu May 20 19:01:46 GMT-05:00 2004
sql.Date: 2004-05-20
sql.Time: 19:01:46
sql.Timestamp: 2004-05-20 19:01:46.593
Note que aún cuando todos los objetos tienen los mismos milisegundos el formato con el que se muestran dependen de la clase que realmente los contiene. Es decir, no importa que a un objeto del tipo java.util.Date se le asigne uno del tipo Time, al mostrar a través de la consola se invocará el método toString() de la clase time:
utilDate = sqlTime;
System.out.println("util.Date apuntando a sql.Time: ["+sqlTime+"]");
utilDate = sqlTimestamp;
System.out.println("util.Date apuntando a sql.Timestamp: ["+sqlTimestamp+"]");
Arroja:
util.Date apuntando a sql.Time: [19:29:47]
util.Date apuntando a sql.Timestamp: [2004-05-20 19:29:47.468]
Pero si en vez de solo apuntar, creamos nuevas instancias con los milisegundos los formatos con que se muestran son los mismos. Note que lo verdaderamente importante ocurre cuando creamos la instancia de java.util.Date usando los milisegundos del objeto sqlTime, pues aunque este último únicamente muestra horas, minutos y segundos, siempre ha conservado todos los datos de la fecha con que se creó.
utilDate = new java.util.Date(sqlTime.getTime());
System.out.println("util.Date con milisegundos de sql.Time: ["+utilDate+"]");
utilDate = new java.util.Date(sqlTimestamp.getTime());
System.out.println("util.Date con milisegundos de sql.Timestamp: ["+utilDate+"]");
Fíjese en el formato de salida:
util.Date con milisegundos de sql.Time: [Thu May 20 19:54:42 GMT-05:00 2004]
util.Date con milisegundos de sql.Timestamp: [Thu May 20 19:54:42 GMT-05:00 2004]
Para finalizar esta primera entrega veamos el código para mostrar la diferencia entre dos fechas en horas, minutos y segundos. Esta no es la mejor forma para hacerlo, pero cabe bien para mostrar de forma práctica todos los conceptos anteriormente estudiados.
import java.util.HashMap;
import java.util.Map;
public class Prueba {
public static Map getDiferencia(java.util.Date fecha1, java.util.Date fecha2){
java.util.Date fechaMayor = null;
java.util.Date fechaMenor = null;
Map resultadoMap = new HashMap();
/* Verificamos cual es la mayor de las dos fechas, para no tener sorpresas al momento
* de realizar la resta.
*/
if (fecha1.compareTo(fecha2) > 0){
fechaMayor = fecha1;
fechaMenor = fecha2;
}else{
fechaMayor = fecha2;
fechaMenor = fecha1;
}
//los milisegundos
long diferenciaMils = fechaMayor.getTime() - fechaMenor.getTime();
//obtenemos los segundos
long segundos = diferenciaMils / 1000;
//obtenemos las horas
long horas = segundos / 3600;
//restamos las horas para continuar con minutos
segundos -= horas*3600;
//igual que el paso anterior
long minutos = segundos /60;
segundos -= minutos*60;
//ponemos los resultados en un mapa :-)
resultadoMap.put("horas",Long.toString(horas));
resultadoMap.put("minutos",Long.toString(minutos));
resultadoMap.put("segundos",Long.toString(segundos));
return resultadoMap;
}
public static void main(String[] args) {
//5:30:00 de Noviembre 10 - 1950 GMT-05:00
java.util.Date fecha1 = new java.util.Date(-604070999750L);
//6:45:20 de Noviembre 10 - 1950 GMT-05:00
java.util.Date fecha2 = new java.util.Date(-604066478813L);
//Luego vemos como obtuve esas fechas
System.out.println(getDiferencia(fecha1, fecha2));
}
}
DIFERENCIA ENTRE FECHAS
Fecha1: Fri Nov 10 05:30:00 GMT-05:00 1950
Fecha2: Fri Nov 10 06:45:21 GMT-05:00 1950
{segundos=20, horas=1, minutos=15}
Operadores Aritméticos
El lenguaje de programación Java tiene varios operadores aritméticos para los datos numéricos enteros y reales. En la siguiente tabla se resumen los diferentes operadores de esta categoría.
Operadores Aritméticos Incrementales
Los operadores aritméticos incrementales son operadores unarios (un único operando). El operando puede ser numérico o de tipo char y el resultado es del mismo tipo que el operando. Estos operadores pueden emplearse de dos formas dependiendo de su posición con respecto al operando.
Combinan un operador aritmético con el operador asignación. Como en el caso de los operadores aritméticos pueden tener operandos numéricos enteros o reales y el tipo específico de resultado numérico dependerá del tipo de éstos. En la siguiente tabla se resumen los diferentes operadores de esta categoría.
1. Las clases java.util.Date y java.sql.Date. Son dos de las clases más usadas cuando una aplicación implica el trabajo con fechas:
java.util.Date: Según la documentación "La clase java.util.Date representa un instante de tiempo específico, con precisión de milisegundos"; esto más que ser una especie de "autoadulación" para la clase, quiere decir que no solo se trata de una simple cadena al estilo yyyy/MM/dd, sino que almacena hasta milisegundos y que es posible trabajar con ellos.
Antes del jdk1.1 la clase java.util.Date tenía dos funciones adicionales a la que conocemos ahora, una de ellas era la interpretación de datos que tenían que ver con fechas, como años, días, segundos, entre otros. La otra era el formateo (la forma como se muestra) y parseo (convertir un String a java.util.Date). Pero debido a las dificultades que presentaban estas funcionalidades a la hora de internacionalizar los programas, esos métodos ya está obsoletos y la clase java.util.Calendar se encargó de esto; así que en este momento esta clase, sólo hace lo que se mencionó al principio: "representa un instante de tiempo específico, con precisión de milisegundos"; más adelante veremos como ampliar esta funcionalidad. Por ahora veamos las convenciones que sigue esta clase:
* El año "y" está representado por un entero igual a ("y" - 1900). Por ejemplo el año 2004 se representa como 104 (2004 - 1900).
* Los meses son representados por números entre 0 y 11, donde enero es 0 y diciembre es 11.
* Los días y minutos se representan de forma corriente. Entre 1 - 31 y 0 - 59 respectivamente.
* Las horas van entre 0 y 23, donde la medianoche es 0 y el medio día 12.
* Los segundos van entre 0 y 61. 61 solo ocurre cuando se agrega el segundo adicional para ajustar la diferencia entre el reloj atómico y el tiempo de rotación de la tierra.
No sobra mencionar que los métodos para obtener el año, mes y día de esta clase ya están obsoletos y lo único que hacen es llamar a la clase java.util.Calendar para que esta se encargue de hacerlo (una delegación).
java.util.Date: Según la documentación "La clase java.util.Date representa un instante de tiempo específico, con precisión de milisegundos"; esto más que ser una especie de "autoadulación" para la clase, quiere decir que no solo se trata de una simple cadena al estilo yyyy/MM/dd, sino que almacena hasta milisegundos y que es posible trabajar con ellos.
Antes del jdk1.1 la clase java.util.Date tenía dos funciones adicionales a la que conocemos ahora, una de ellas era la interpretación de datos que tenían que ver con fechas, como años, días, segundos, entre otros. La otra era el formateo (la forma como se muestra) y parseo (convertir un String a java.util.Date). Pero debido a las dificultades que presentaban estas funcionalidades a la hora de internacionalizar los programas, esos métodos ya está obsoletos y la clase java.util.Calendar se encargó de esto; así que en este momento esta clase, sólo hace lo que se mencionó al principio: "representa un instante de tiempo específico, con precisión de milisegundos"; más adelante veremos como ampliar esta funcionalidad. Por ahora veamos las convenciones que sigue esta clase:
* El año "y" está representado por un entero igual a ("y" - 1900). Por ejemplo el año 2004 se representa como 104 (2004 - 1900).
* Los meses son representados por números entre 0 y 11, donde enero es 0 y diciembre es 11.
* Los días y minutos se representan de forma corriente. Entre 1 - 31 y 0 - 59 respectivamente.
* Las horas van entre 0 y 23, donde la medianoche es 0 y el medio día 12.
* Los segundos van entre 0 y 61. 61 solo ocurre cuando se agrega el segundo adicional para ajustar la diferencia entre el reloj atómico y el tiempo de rotación de la tierra.
No sobra mencionar que los métodos para obtener el año, mes y día de esta clase ya están obsoletos y lo único que hacen es llamar a la clase java.util.Calendar para que esta se encargue de hacerlo (una delegación).
java.sql.Date: Esta clase hereda de java.util.Date y es la representación de la fecha cuando trabajamos con JDBC (Java DabaBase Connectivity), es decir, son los campos almacenados en una base de datos cuyo tipo es una fecha que puede o no incluir la hora, aunque la clase java.sql.Date siempre lo hace. Al igual que su clase padre, tiene una precisión de milisegundos, con la excepción que al mostrarla en la salida estándar con el formato por defecto solo muestra el día, mes y año. Hay que anotar también que para campos que almacenen solamente horas existen otras clases para manejarlos.
En resumen ambas clases, sólo se encargan de almacenar la cantidad de milisegundos que han pasado desde las 12 de la noche del primero de enero de 1970 en el meridiano de Greenwich. Aquí vienen dos puntos importantes:
a) Si la fecha que almacena cualquiera de las clases es menor a las 00:00:00 enero 1 de 1970 GMT, su valor el milisegundos será negativo.
b) La fecha es susceptible a la zona horaria. Por ejemplo en Colombia los milisegundos no se empiezan a contar desde enero 1 de 1970, sino a partir de las 19:00 de diciembre 31 de 1969. Esto es importante por que si transportamos una fecha relativa de una zona a otra, podemos llegar a tener problemas al confiar en los milisegundos que se tienen; además como la clase intenta representar el "Tiempo Universal Coordinado" (UTC) suma 0.9 segundos cada año para ajustar la diferencia entre el reloj atómico y la velocidad de rotación de la tierra. Esto se traduce en que muy dificilmente podemos basarnos en valores como 0 o 60000 para realizar validaciones, pues esos milisegundos no son controlables cuando creamos la instancia de una fecha, peor aún, los milisegundos no son ni siquiera iguales para la misma fecha en la misma zona horaria.
a) Si la fecha que almacena cualquiera de las clases es menor a las 00:00:00 enero 1 de 1970 GMT, su valor el milisegundos será negativo.
b) La fecha es susceptible a la zona horaria. Por ejemplo en Colombia los milisegundos no se empiezan a contar desde enero 1 de 1970, sino a partir de las 19:00 de diciembre 31 de 1969. Esto es importante por que si transportamos una fecha relativa de una zona a otra, podemos llegar a tener problemas al confiar en los milisegundos que se tienen; además como la clase intenta representar el "Tiempo Universal Coordinado" (UTC) suma 0.9 segundos cada año para ajustar la diferencia entre el reloj atómico y la velocidad de rotación de la tierra. Esto se traduce en que muy dificilmente podemos basarnos en valores como 0 o 60000 para realizar validaciones, pues esos milisegundos no son controlables cuando creamos la instancia de una fecha, peor aún, los milisegundos no son ni siquiera iguales para la misma fecha en la misma zona horaria.
Ambas clases se pueden instanciar directamente mediante new(), pero la clase java.sql.Date necesita un parámetro en el constructor: el tiempo en milisegundos, así que las siguientes instrucciones son válidas:
java.util.Date fechaActual = new java.util.Date(); //Fecha actual del sistema java.sql.Date inicioLocal = new java.sql.Date(0); //Milisegundo cero //también se puede crear una instancia de java.util.Date con parámetros iniciales java.util.Date otraFecha = new java.util.Date(1000); //El primer segundo a partir del inicio
Prueba a imprimir cada uno de estos valores y fíjate en la diferencia de formatos entre java.sql.Date y java.util.Date. Se puede pasar de java.sql.Date a java.util.Date de dos fomas, una de ellas es con una asignación simple:
java.util.Date utilDate = null; java.sql.Date sqlDate = new java.sql.Date(0); utilDate = sqlDate; /* aunque es java.util.Date, si la imprimes tendrá el formato de java.sql.Date, recordemos que java.sql.Date hereda de java.util.Date */ System.out.println(utilDate);
También se pueden tomar los milisegundos de java.sql.Date y pasarlos al constructor de java.util.Date:
java.util.Date utilDate = null; java.sql.Date sqlDate = new java.sql.Date(0); utilDate = new java.util.Date(sqlDate.getTime()); //esta vez se mostrará con el formato de java.util.Date System.out.println(utilDate);
Para pasar de java.util.Date a java.sql.Date se deben tomar los milisegundos de la primera y pasarlos al constructor de la segunda:
java.util.Date utilDate = new java.util.Date(); java.sql.Date sqlDate = new java.sql.Date(utilDate.getTime()); //Con formato de java.sql.Date System.out.println(sqlDate);
Para comparar fechas usamos el método compareTo() que internamente compara los milisegundos entre ellas usando directamente los métodos getTime() de ambas clases.
java.util.Date utilDate = new java.util.Date(); java.sql.Date sqlDate = new java.sql.Date(utilDate.getTime()); if (utilDate.compareTo(sqlDate) == 0){ System.out.println("IGUALES"); }else{ System.out.println("DIFERENTES"); }
O lo que es equivalente:
java.util.Date utilDate = new java.util.Date(); java.sql.Date sqlDate = new java.sql.Date(utilDate.getTime()); if (utilDate.getTime() == sqlDate.getTime()){ System.out.println("IGUALES"); }else{ System.out.println("DIFERENTES"); }
2. Las clases Time y Timestamp.
Ambas clases pertenecen al API JDBC y son la encargadas de representar los campos de estos tipos en una base de datos. Esto no quiere decir que no se puedan usar con otros fines. Al igual que java.sql.Date, son hijas (heredan) de java.util.Date, es decir, su núcleo son los milisegundos.
La clase Time es un envoltorio de la clase java.util.Date para representar los datos que consisten de horas, minutos, segundos y milisegundos, mientras Timestamp representa estos mísmos datos más un atributo con nanosegundos, de acuerdo a las especificaciones del lenguaje SQL para campos de tipo TIMESTAMP.
Como ambas clases heredan del java.util.Date, es muy fácil pasar de un tipo de dato a otro; similar a la clase java.sql.Date, tanto Time como Timestamp se pueden instanciar directamente y su constructor tiene como parámetro el número de milisegundos; como es de imaginarse, cuando se muestra alguna de las clases mediante su método toString() se ven los datos que intentan representar; La clase Time sólamente muestra la hora, minutos y segundo, mientras timestamp agrega fracciones de segundo a la cadena.
Para convertir entre tipos de datos diferentes debemos usar los milisegundos de una clase y asignarlos a las instancias de las otras, y como la clase java.util.Date es superclase de todas, a una instancia de esta podemos asignar cualquiera de las otras, manteniendo los métodos de la clase asignada, es decir, si asignamos un Time a una java.util.Date, al imprimir se verá el mismo formato de la clase Time.
Con este código:
Ambas clases pertenecen al API JDBC y son la encargadas de representar los campos de estos tipos en una base de datos. Esto no quiere decir que no se puedan usar con otros fines. Al igual que java.sql.Date, son hijas (heredan) de java.util.Date, es decir, su núcleo son los milisegundos.
La clase Time es un envoltorio de la clase java.util.Date para representar los datos que consisten de horas, minutos, segundos y milisegundos, mientras Timestamp representa estos mísmos datos más un atributo con nanosegundos, de acuerdo a las especificaciones del lenguaje SQL para campos de tipo TIMESTAMP.
Como ambas clases heredan del java.util.Date, es muy fácil pasar de un tipo de dato a otro; similar a la clase java.sql.Date, tanto Time como Timestamp se pueden instanciar directamente y su constructor tiene como parámetro el número de milisegundos; como es de imaginarse, cuando se muestra alguna de las clases mediante su método toString() se ven los datos que intentan representar; La clase Time sólamente muestra la hora, minutos y segundo, mientras timestamp agrega fracciones de segundo a la cadena.
Para convertir entre tipos de datos diferentes debemos usar los milisegundos de una clase y asignarlos a las instancias de las otras, y como la clase java.util.Date es superclase de todas, a una instancia de esta podemos asignar cualquiera de las otras, manteniendo los métodos de la clase asignada, es decir, si asignamos un Time a una java.util.Date, al imprimir se verá el mismo formato de la clase Time.
Con este código:
java.util.Date utilDate = new java.util.Date(); //fecha actual long lnMilisegundos = utilDate.getTime(); java.sql.Date sqlDate = new java.sql.Date(lnMilisegundos); java.sql.Time sqlTime = new java.sql.Time(lnMilisegundos); java.sql.Timestamp sqlTimestamp = new java.sql.Timestamp(lnMilisegundos); System.out.println("util.Date: "+utilDate); System.out.println("sql.Date: "+sqlDate); System.out.println("sql.Time: "+sqlTime); System.out.println("sql.Timestamp: "+sqlTimestamp);
Se obtiene la siguiente salida:
util.Date: Thu May 20 19:01:46 GMT-05:00 2004
sql.Date: 2004-05-20
sql.Time: 19:01:46
sql.Timestamp: 2004-05-20 19:01:46.593
Note que aún cuando todos los objetos tienen los mismos milisegundos el formato con el que se muestran dependen de la clase que realmente los contiene. Es decir, no importa que a un objeto del tipo java.util.Date se le asigne uno del tipo Time, al mostrar a través de la consola se invocará el método toString() de la clase time:
utilDate = sqlTime; System.out.println("util.Date apuntando a sql.Time: ["+sqlTime+"]"); utilDate = sqlTimestamp; System.out.println("util.Date apuntando a sql.Timestamp: ["+sqlTimestamp+"]");
Arroja:
util.Date apuntando a sql.Time: [19:29:47]
util.Date apuntando a sql.Timestamp: [2004-05-20 19:29:47.468]
Pero si en vez de solo apuntar, creamos nuevas instancias con los milisegundos los formatos con que se muestran son los mismos. Note que lo verdaderamente importante ocurre cuando creamos la instancia de java.util.Date usando los milisegundos del objeto sqlTime, pues aunque este último únicamente muestra horas, minutos y segundos, siempre ha conservado todos los datos de la fecha con que se creó.
utilDate = new java.util.Date(sqlTime.getTime()); System.out.println("util.Date con milisegundos de sql.Time: ["+utilDate+"]"); utilDate = new java.util.Date(sqlTimestamp.getTime()); System.out.println("util.Date con milisegundos de sql.Timestamp: ["+utilDate+"]");
Fíjese en el formato de salida:
util.Date con milisegundos de sql.Time: [Thu May 20 19:54:42 GMT-05:00 2004]
util.Date con milisegundos de sql.Timestamp: [Thu May 20 19:54:42 GMT-05:00 2004]
Para finalizar esta primera entrega veamos el código para mostrar la diferencia entre dos fechas en horas, minutos y segundos. Esta no es la mejor forma para hacerlo, pero cabe bien para mostrar de forma práctica todos los conceptos anteriormente estudiados.
import java.util.HashMap; import java.util.Map; public class Prueba { public static Map getDiferencia(java.util.Date fecha1, java.util.Date fecha2){ java.util.Date fechaMayor = null; java.util.Date fechaMenor = null; Map resultadoMap = new HashMap(); /* Verificamos cual es la mayor de las dos fechas, para no tener sorpresas al momento * de realizar la resta. */ if (fecha1.compareTo(fecha2) > 0){ fechaMayor = fecha1; fechaMenor = fecha2; }else{ fechaMayor = fecha2; fechaMenor = fecha1; } //los milisegundos long diferenciaMils = fechaMayor.getTime() - fechaMenor.getTime(); //obtenemos los segundos long segundos = diferenciaMils / 1000; //obtenemos las horas long horas = segundos / 3600; //restamos las horas para continuar con minutos segundos -= horas*3600; //igual que el paso anterior long minutos = segundos /60; segundos -= minutos*60; //ponemos los resultados en un mapa :-) resultadoMap.put("horas",Long.toString(horas)); resultadoMap.put("minutos",Long.toString(minutos)); resultadoMap.put("segundos",Long.toString(segundos)); return resultadoMap; } public static void main(String[] args) { //5:30:00 de Noviembre 10 - 1950 GMT-05:00 java.util.Date fecha1 = new java.util.Date(-604070999750L); //6:45:20 de Noviembre 10 - 1950 GMT-05:00 java.util.Date fecha2 = new java.util.Date(-604066478813L); //Luego vemos como obtuve esas fechas System.out.println(getDiferencia(fecha1, fecha2)); } }
DIFERENCIA ENTRE FECHAS
Fecha1: Fri Nov 10 05:30:00 GMT-05:00 1950
Fecha2: Fri Nov 10 06:45:21 GMT-05:00 1950
{segundos=20, horas=1, minutos=15}
Paquete java.time de Java 8: Fechas y horas
En este artículo veremos sobre un nuevo paquete que existe en Java 8, se trata del paquete java.time. Este paquete es una extensión a las clases java.util.Date y java.util.Calendar que vemos un poco limitado para manejo de fechas, horas y localización.
Las clases definidas en este paquete representan los principales conceptos de fecha - hora, incluyendo instantes, fechas, horas, periodos, zonas de tiempo, etc. Están basados en el sistema de calendario ISO, el cual el calendario mundial de-facto que sigue las reglas del calendario Gregoriano
Enumerados de mes y de día de la semana
Existe un enum donde se definen todos los días de la semana. Lo cual tiene sentido hacerlo enum porque siempre habrán siete días de la semana :). Este enum se llama java.time.DayOfWeek
Existe un enum donde se definen todos los días de la semana. Lo cual tiene sentido hacerlo enum porque siempre habrán siete días de la semana :). Este enum se llama java.time.DayOfWeek
DayOfWeek lunes = DayOfWeek.MONDAY;
Este enum tiene algunos métodos interesantes que permite manipular días hacía adelante y hacia atrás:
DayOfWeek lunes = DayOfWeek.MONDAY;
System.out.printf("8 días será: %s%n",lunes.plus(8));
System.out.printf("2 días antes fue: %s%n",lunes.minus(2));
Además, con el método getDisplayName() se puede acceder al texto que corresponde a la fecha, dependiendo del Locale actual, o el que definamos. Para mi país probé con esto:
DayOfWeek lunes = DayOfWeek.MONDAY;
Locale l = new Locale("es","PE");
System.out.println("TextStyle.FULL:" + lunes.getDisplayName(TextStyle.FULL, l));
System.out.println("TextStyle.NARROW:" + lunes.getDisplayName(TextStyle.NARROW, l));
System.out.println("TextStyle.SHORT:" + lunes.getDisplayName(TextStyle.SHORT, l));
Deberían probar con Locale l = Locale.KOREA, es muy interesante lo que sale.
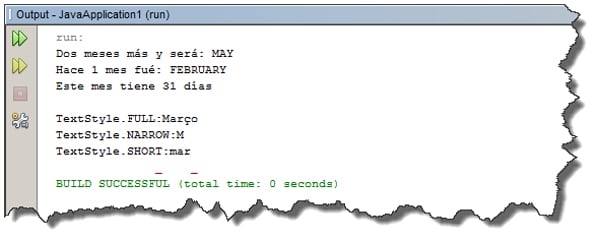
Para los meses, existe el enum java.time.Month que básicamente hace lo mismo:
Locale l = new Locale("pt"); //probamos con portugues
Month mes = Month.MARCH;
System.out.printf("Dos meses más y será: %s%n", mes.plus(2));
System.out.printf("Hace 1 mes fué: %s%n", mes.minus(1));
System.out.printf("Este mes tiene %s días %n ", mes.maxLength());
System.out.printf("TextStyle.FULL:%s%n", mes.getDisplayName(TextStyle.FULL, l));
System.out.printf("TextStyle.NARROW:%s%n", mes.getDisplayName(TextStyle.NARROW, l));
System.out.printf("TextStyle.SHORT:%s%n", mes.getDisplayName(TextStyle.SHORT, l));
.. y el resultado sería así:
Funciones Básicas con Cadenas
Una vez que hemos visto lo sencillo que es crear una cadena de textovamos a echar un vistazo a los métodos que nos permiten manipular la cadena de texto. Si tuviésemos que ordenar dichos métodos podríamos llegar a la siguiente división:
- Información básica de la cadena
- Comparación de Cadenas
- Búsqueda de caracteres
- Búsqueda de subcadenas
- Manejo de subcadenas
- Manejo de caracteres
- Conversión a String: valueOf()
Información básica de la cadena
.length() Nos devuelve el tamaño que tiene la cadena.
char charAt(int index) Devuelve el carácter indicado como índice. El primer carácter de la cadena será el del índice 0. Junto con el método
.length() podemos recuperar todos los caracteres de la cadena de texto. Hay que tener cuidado. Ya que si intentamos acceder a un índice de carácter que no existe nos devolverá una excepción IndexOutOfBoundsException.Comparación de Cadenas
Los métodos de comparación nos sirven para comparar si dos cadenas de texto son iguales o no. Dentro de los métodos de comparación tenemos los siguientes:
boolean equals(Object anObject) Nos permite comparar si dos cadenas de texto son iguales. En el caso de que sean iguales devolverá como valor “true”. En caso contrario devolverá “false”. Este método tiene en cuenta si los caracteres van en mayúsculas o en minúsculas. Si queremos omitir esta validación tenemos dos opciones. La primera es convertir las cadenas a mayúsculas o minúsculas con los métodos
.toUpperCase() y .toLowerCase() respectivamente. Métodos que veremos más adelante. La segunda opción es utilizar el método .equalsIgnoreCase() que omite si el carácter está en mayúsculas o en minúsculas.
boolean equalsIgnoreCase(String anotherString) Compara dos cadenas de caracteres omitiendo si los caracteres están en mayúsculas o en minúsculas.
int compareTo(String anotherString) Este método es un poco más avanzado que el anterior, el cual, solo nos indicaba si las cadenas eran iguales o diferentes En este caso compara a las cadenas léxicamente. Para ello se basa en el valor Unicode de los caracteres. Se devuelve un entero menor de 0 si la cadena sobre la que se parte es léxicamente menor que la cadena pasada como argumento. Si las dos cadenas son iguales léxicamente se devuelve un 0. Si la cadena es mayor que la pasada como argumento se devuelve un número entero positivo. Pero que es esto de “mayor, menor o igual léxicamente”. Para describirlo lo veremos con un pequeño ejemplo.
s1 = "Cuervo"
s2 = "Cuenca"
s1.compareTo(s2);
Compararíamos las dos cadenas. Los tres primeros caracteres son iguales “Cue”. Cuando el método llega al 4 carácter tiene que validar entre la r minúscula y la n minúscula. Si utiliza el código Unicode llegará a la siguiente conclusión.
r (114) > n(110)
Y nos devolverá la resta de sus valores. En este caso un 4. Hay que tener cuidado, porque este método no tiene en cuenta las mayúsculas y minúsculas. Y dichos caracteres, aún siendo iguales, tienen diferentes código. Veamos la siguiente comparación
s1 = "CueRvo"
s2 = "Cuervo"
s1.compareTo(s2);
Nuevamente los tres caracteres iniciales son iguales. Pero el cuarto es distinto. Por un lado tenemos la r minúscula y por otro la r mayúscula. Así:
R(82) < r(114)
¿Qué entero nos devolverá el método compareTo()? ¿-32?
int compareToIgnoreCase(String str) Este método se comportará igual que el anterior. Pero ignorando las mayúsculas. Todo un alivio por si se nos escapa algún carácter en mayúsculas ;-) Otros métodos para la comparación de cadenas son:
boolean regionMatch( int thisoffset,String s2,int s2offset,int len );
boolean regionMatch( boolean ignoreCase,int thisoffset,String s2, int s2offset,int 1 );
Búsqueda de caracteres
Tenemos un conjunto de métodos que nos permiten buscar caracteres dentro de cadenas de texto. Y es que no nos debemos de olvidar que la cadena de caracteres no es más que eso: una suma de caracteres.
int indexOf(int ch) Nos devuelve la posición de un carácter dentro de la cadena de texto. En el caso de que el carácter buscado no exista nos devolverá un -1. Si lo encuentra nos devuelve un número entero con la posición que ocupa en la cadena.
int indexOf(int ch, int fromIndex) Realiza la misma operación que el anterior método, pero en vez de hacerlo a lo largo de toda la cadena lo hace desde el índice (fromIndex) que le indiquemos.
int lastIndexOf(int ch) Nos indica cual es la última posición que ocupa un carácter dentro de una cadena. Si el carácter no está en la cadena devuelve un -1. int lastIndexOf(int ch, int fromIndex) Lo mismo que el anterior, pero a partir de una posición indicada como argumento.
Búsqueda de subcadenas
Este conjunto de métodos son, probablemente, los más utilizados para el manejo de cadenas de caracteres. Ya que nos permiten buscar cadenas dentro de cadenas, así como saber la posición donde se encuentran en la cadena origen para poder acceder a la subcadena. Dentro de este conjunto encontramos:
int indexOf(String str) Busca una cadena dentro de la cadena origen. Devuelve un entero con el índice a partir del cual está la cadena localizada. Si no encuentra la cadena devuelve un -1.
int indexOf(String str, int fromIndex) Misma funcionalidad que
indexOf(String str), pero a partir de un índice indicado como argumento del método.
int lastIndexOf(String str) Si la cadena que buscamos se repite varias veces en la cadena origen podemos utilizar este método que nos indicará el índice donde empieza la última repetición de la cadena buscada.
lastIndexOf(String str, int fromIndex) Lo mismo que el anterior, pero a partir de un índice pasado como argumento.
boolean startsWith(String prefix) Probablemente mucha gente se haya encontrado con este problema. El de saber si una cadena de texto empieza con un texto específico. La verdad es que este método podía obviarse y utilizarse el
indexOf(), con el cual, en el caso de que nos devolviese un 0, sabríamos que es el inicio de la cadena.
boolean startsWith(String prefix, int toffset) Más elaborado que el anterior, y quizás, y a mi entender con un poco menos de significado que el anterior.
boolean endsWith(String suffix) Y si alguien se ha visto con la necesidad de saber si una cadena empieza por un determinado texto, no va a ser menos el que se haya preguntado si la cadena de texto acaba con otra. De igual manera que sucedía con el método
.startsWith() podríamos utilizar una mezcla entre los métodos .indexOf() y .length() para reproducir el comportamiento de .endsWith(). Pero las cosas, cuanto más sencillas, doblemente mejores.Métodos con subcadenas
Ahora que sabemos como localizar una cadena dentro de otra seguro que nos acucia la necesidad de saber como substraerla de donde está. Si es que no nos podemos estar quietos…
String substring(int beginIndex) Este método nos devolverá la cadena que se encuentra entre el índice pasado como argumento (beginIndex) hasta el final de la cadena origen. Así, si tenemos la siguiente cadena:
String s = "Víctor Cuervo";
El método…
s.substring(7);
Nos devolverá “Cuervo”.
String substring(int beginIndex, int endIndex) Si se da el caso que la cadena que queramos recuperar no llega hasta el final de la cadena origen, que será lo normal, podemos utilizar este método indicando el índice inicial y final del cual queremos obtener la cadena. Así, si partimos de la cadena…
String s = "En un lugar de la mancha....";
El método…
s.substring(6,11);
Nos devolverá la palabra “lugar”.
Hay que tener especial cuidado ya que es un error muy común el poner como índice final el índice del carácter último de la palabra a extraer. Cuando realmente es el índice + 1 de lo que queramos obtener.
Manejo de caracteres
Otro conjunto de métodos que nos permite jugar con los caracteres de la cadena de texto. Para ponerles en mayúsculas, minúsculas, quitarles los espacios en blanco, reemplazar caracteres,….
String toLowerCase(); Convierte todos los caracteres en minúsculas.
String toUpperCase(); Convierte todos los caracteres a mayúsculas.
String trim(); Elimina los espacios en blanco de la cadena.
String replace(char oldChar, char newChar) Este método lo utilizaremos cuando lo que queramos hacer sea el remplazar un carácter por otro. Se reemplazarán todos los caracteres encontrados.
Conversión a String: valueOf()
Un potente conjunto de métodos de la clase
String nos permite convertir a cadena cualquier tipo de dato básico: int, float, double,… Esto es especialmente útil cuando hablamos de números. Ya que en múltiples ocasiones querremos mostrarles como cadenas de texto y no en su representación normal de número. Así podemos utilizar los siguientes métodos:- String valueOf(boolean b);
- String valueOf(int i);
- String valueOf(long l);
- String valueOf(float f);
- String valueOf(double d);
- String valueOf(Object obj);
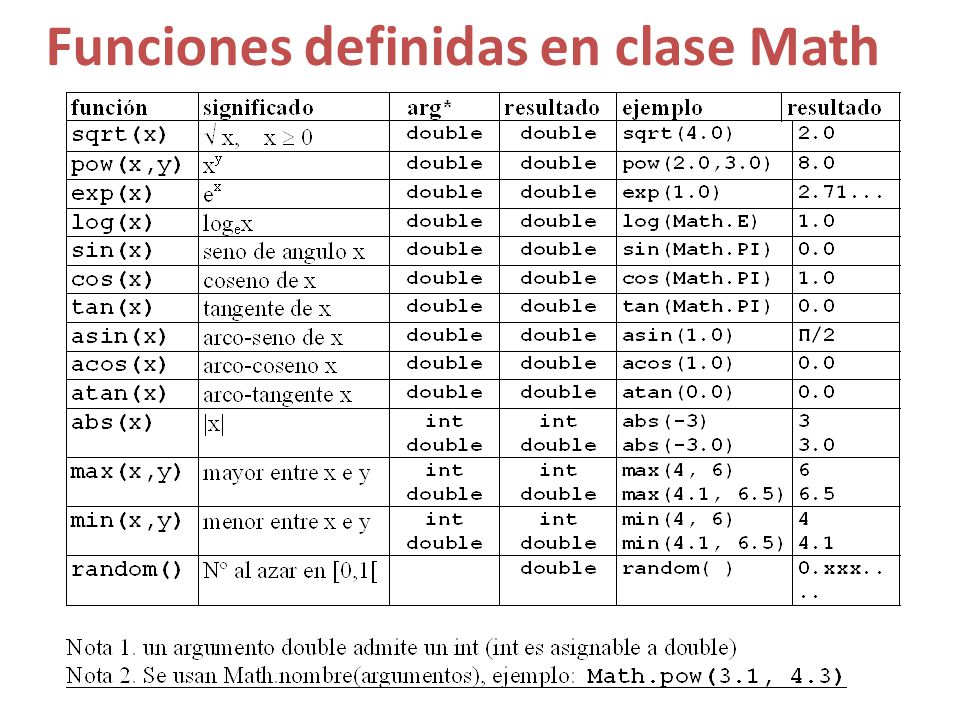
Clase Math
Esta clase ya viene incluida en nuevas versiones de Java, por lo que no habrá que importar ningún paquete para ello.
Para utilizar esta clase, debemos escribir Math.método(parámetros); donde método sera uno de los siguientes y parámetros aquellos que tengamos que usar. Un método puede estar sobrescrito para distintos tipos de datos.
 En el ejemplo anterior devuelve un numero aleatorio.
En el ejemplo anterior devuelve un numero aleatorio.
Sentencias de control del flujo de un programa
Cuando se escribe un programa, se introduce la secuencia de sentencias dentro de un archivo. Sin sentencias de control del flujo, el intérprete ejecuta las sentencias conforme aparecen en el programa de principio a fin. Las sentencias de control de flujo se emplean en los programas para ejecutar sentencias condicionalmente, repetir un conjunto de sentencias o, en general, cambiar el flujo secuencial de ejecución.
Sentencia if / if - else / if - else if

La clase Math representa la librería matemática de Java. Las funciones que contiene son las de todos los lenguajes, parece que se han metido en una clase solamente a propósito de agrupación, por eso se encapsulan en Math, y lo mismo sucede con las demás clases que corresponden a objetos que tienen un tipo equivalente (Character, Float, etc.). El constructor de la clase es privado, por los que no se pueden crear instancias de la clase. Sin embargo, Math es public para que se pueda llamar desde cualquier sitio y static para que no haya que inicializarla.
Para utilizar esta clase, debemos escribir Math.método(parámetros); donde método sera uno de los siguientes y parámetros aquellos que tengamos que usar. Un método puede estar sobrescrito para distintos tipos de datos.

Sentencias de control del flujo de un programa
Cuando se escribe un programa, se introduce la secuencia de sentencias dentro de un archivo. Sin sentencias de control del flujo, el intérprete ejecuta las sentencias conforme aparecen en el programa de principio a fin. Las sentencias de control de flujo se emplean en los programas para ejecutar sentencias condicionalmente, repetir un conjunto de sentencias o, en general, cambiar el flujo secuencial de ejecución.
Sentencia if / if - else / if - else if
Es una bifurcación o sentencia condicional de una o dos ramas. La sentencia de control evalúa la condición lógica o booleana. Si esta condición es cierta entonces se ejecuta la sentencia o sentencias (1) que se encuentra a continuacion. En caso contrario, se ejecuta la sentencia (2) que sigue a
else (si ésta existe). La sentencia puede constar opcionalmente de una o dos ramas con sus correspondientes sentencias.
Sintaxis:
if (expresionLogica) { sentencia_1; }
o bien (con dos ramas):
if (expresionLogica) { sentencia_1; } else { sentencia_2; }
La
expresionLogica debe ir entre paréntesis. Las llaves sólo son obligatorias si las sentencias (1) ó (2) son compuestas (las llaves sirven para agrupar varias sentencias simples).
La parte
else y la sentencia posterior entre llaves no son obligatorias. En este caso quedaría una sentencia selectiva con una rama.
Un ejemplo muy sencillo que muestra este tipo de sentencia es el siguiente:
// Codigo autoexplicativo if (a>b) { System.out.println("a es mayor que b"); }else { System.out.println("a no es mayor que b"); }
Sentencias repetitivas, iterativas o bucles
Los bucles, iteraciones o sentencias repetitivas modifican el flujo secuencial de un programa permitiendo la ejecución reiterada de una sentencia o sentencias. En Java hay tres tipos diferentes de bucles: for, while y do-while.
Sentencia for
Sintaxis:
for (inicio; termino; iteracion)
sentencia;
O si se desean repetir varias sentencias:
for (inicio; termino; iteracion) {
sentencia_1;
sentencia_2;
sentencia_n;
}
Las llaves sólo son necesarias si se quieren repetir varias sentencias, aunque se recomienda su porque facilita la lectura del código fuente y ayuda a evitar errores al modificarlo. Habitualmente, en la expresión lógica de término se verifica que la variable de control alcance un uso determinado valor. Por ejemplo:
for (i = valor_inicial; i <= valor_final; i++) {
sentencia;
}
Es completamente legal en Java declarar una variable dentro de la cabecera de un bucle for. De esta forma la variable (local) sólo tiene ámbito dentro del bucle. Ejemplo sencillo:
System.out.println("Tabla de multiplicar del 5");
for (int i =0 ; i <= 10; i++) {
System.out.println(5 + " * " + i + " = " + 5 * i);
}
Salida por pantalla al ejecutar el código anterior:
5 * 0 = 0
5 * 1 = 5
5 * 2 = 10
5 * 3 = 15
5 * 4 = 20
5 * 5 = 25
5 * 6 = 30
5 * 7 = 35
5 * 8 = 40
5 * 9 = 45
5 * 10 = 50
Sentencias repetitivas, iterativas o bucles
Los bucles, iteraciones o sentencias repetitivas modifican el flujo secuencial de un programa permitiendo la ejecución reiterada de una sentencia o sentencias. En Java hay tres tipos diferentes de bucles:
for, while y do-while.
Sentencia for

Sintaxis:
for (inicio; termino; iteracion) sentencia;
O si se desean repetir varias sentencias:
for (inicio; termino; iteracion) { sentencia_1; sentencia_2; sentencia_n; }
Las llaves sólo son necesarias si se quieren repetir varias sentencias, aunque se recomienda su porque facilita la lectura del código fuente y ayuda a evitar errores al modificarlo. Habitualmente, en la expresión lógica de término se verifica que la variable de control alcance un uso determinado valor. Por ejemplo:
for (i = valor_inicial; i <= valor_final; i++) { sentencia; }
Es completamente legal en Java declarar una variable dentro de la cabecera de un bucle
for. De esta forma la variable (local) sólo tiene ámbito dentro del bucle. Ejemplo sencillo:System.out.println("Tabla de multiplicar del 5"); for (int i =0 ; i <= 10; i++) { System.out.println(5 + " * " + i + " = " + 5 * i); }
Salida por pantalla al ejecutar el código anterior:
5 * 0 = 0 5 * 1 = 5 5 * 2 = 10 5 * 3 = 15 5 * 4 = 20 5 * 5 = 25 5 * 6 = 30 5 * 7 = 35 5 * 8 = 40 5 * 9 = 45 5 * 10 = 50
For-each
En las últimas versiones de Java se introdujo una nueva forma de uso del for, a la que se denomina “for extendido” o “for each”. Esta forma de uso del for, que ya existía en otros lenguajes, facilita el recorrido de objetos existentes en una colección sin necesidad de definir el número de elementos a recorrer. La sintaxis que se emplea es:
for ( TipoARecorrer nombreVariableTemporal : nombreDeLaColección ) {
Instrucciones
}
Fíjate que en ningún momento se usa la palabra clave each que se usa en otros lenguajes, aunque al for muchas veces se le nombre como for each. Para saber si un for es un for extendido o un for normal hemos de fijarnos en la sintaxis que se emplea. La interpretación que podemos hacer de la sintaxis del for extendido es: “Para cada elemento del tipo TipoARecorrer que se encuentre dentro de la colección nombreDeLaColección ejecuta las instrucciones que se indican”. La variable local-temporal del ciclo almacena en cada paso el objeto que se visita y sólo existe durante la ejecución del ciclo y desaparece después. Debe ser del mismo tipo que los elementos a recorrer. Ejemplo
//Ejemplo aprenderaprogramar.com
public void listarTodosLosNombres () {
for (String i: listaDeNombres) {
System.out.println (i); //Muestra cada uno de los nombres dentro de listaDeNombres
}
}
En este tipo de ciclos podemos darle un nombre más descriptivo a la variable temporal, por ejemplo:
//Ejemplo aprenderaprogramar.com
public void listarTodosLosNombres () {
for (String nombre: listaDeNombres) {
System.out.println (nombre); }
}
Un ejemplo de llamada desde un método main (u otro lugar) sería:
//Ejemplo aprenderaprogramar.com
System.out.println ("Mostramos todos los nombres con un ciclo for-each");
lista1.listarTodosLosNombres();
El for extendido tiene algunas ventajas y algunos inconvenientes. No se debe usar siempre. Su uso no es obligatorio, de hecho, como hemos indicado, en versiones anteriores ni siquiera existía en el lenguaje. En vez de un for extendido podemos preferir usar un ciclo while. Lo haríamos así:
//Ejemplo aprenderaprogramar.com
int i = 0;
while (i < lista1.size() ) { System.out.println (lista1.getNombre(i) );
i++; }
El ciclo for-each es una herramienta muy útil cuando tenemos que realizar recorridos completos de colecciones, por lo que lo usaremos en numerosas ocasiones antes que ciclos for o while que nos obligan a estar pendientes de más cuestiones (por ejemplo en este caso con el while, de llevar un contador, llamar en cada iteración a un método, etc.). Un for extendido en principio recorre todos y cada uno de los elementos de una colección. Sin embargo, podemos introducir un condicional asociado a una sentencia break; que aborte el recorrido una vez se cumpla una determinada condición. Escribe y compila el siguiente código ejemplo de uso de un for extendido:
import java.util.ArrayList;
//Test del for extendido ejemplo aprenderaprogramar.com
public class TestForExtendido {
public static void main (String [] Args) {
ArrayList <String> jugadoresDeBaloncesto = new ArrayList<String> ();
jugadoresDeBaloncesto.add ("Michael Jordan"); jugadoresDeBaloncesto.add ("Kobe Briant");
jugadoresDeBaloncesto.add ("Pau Gasol"); jugadoresDeBaloncesto.add ("Drazen Petrovic");
int i = 0;
System.out.println ("Los jugadores de baloncesto en la lista son: ");
for (String nombre : jugadoresDeBaloncesto) { System.out.println ((i+1) + ".- " +nombre);
i++; }
} //Cierre del main
} //Cierre de la clase
for ( TipoARecorrer nombreVariableTemporal : nombreDeLaColección ) {
Instrucciones
}
|
Fíjate que en ningún momento se usa la palabra clave each que se usa en otros lenguajes, aunque al for muchas veces se le nombre como for each. Para saber si un for es un for extendido o un for normal hemos de fijarnos en la sintaxis que se emplea. La interpretación que podemos hacer de la sintaxis del for extendido es: “Para cada elemento del tipo TipoARecorrer que se encuentre dentro de la colección nombreDeLaColección ejecuta las instrucciones que se indican”. La variable local-temporal del ciclo almacena en cada paso el objeto que se visita y sólo existe durante la ejecución del ciclo y desaparece después. Debe ser del mismo tipo que los elementos a recorrer. Ejemplo
//Ejemplo aprenderaprogramar.com
public void listarTodosLosNombres () {
for (String i: listaDeNombres) {
System.out.println (i); //Muestra cada uno de los nombres dentro de listaDeNombres
}
}
|
En este tipo de ciclos podemos darle un nombre más descriptivo a la variable temporal, por ejemplo:
//Ejemplo aprenderaprogramar.com
public void listarTodosLosNombres () {
for (String nombre: listaDeNombres) {
System.out.println (nombre); }
}
|
Un ejemplo de llamada desde un método main (u otro lugar) sería:
//Ejemplo aprenderaprogramar.com
System.out.println ("Mostramos todos los nombres con un ciclo for-each");
lista1.listarTodosLosNombres();
|
El for extendido tiene algunas ventajas y algunos inconvenientes. No se debe usar siempre. Su uso no es obligatorio, de hecho, como hemos indicado, en versiones anteriores ni siquiera existía en el lenguaje. En vez de un for extendido podemos preferir usar un ciclo while. Lo haríamos así:
//Ejemplo aprenderaprogramar.com
int i = 0;
while (i < lista1.size() ) { System.out.println (lista1.getNombre(i) );
i++; }
|
El ciclo for-each es una herramienta muy útil cuando tenemos que realizar recorridos completos de colecciones, por lo que lo usaremos en numerosas ocasiones antes que ciclos for o while que nos obligan a estar pendientes de más cuestiones (por ejemplo en este caso con el while, de llevar un contador, llamar en cada iteración a un método, etc.). Un for extendido en principio recorre todos y cada uno de los elementos de una colección. Sin embargo, podemos introducir un condicional asociado a una sentencia break; que aborte el recorrido una vez se cumpla una determinada condición. Escribe y compila el siguiente código ejemplo de uso de un for extendido:
import java.util.ArrayList;
//Test del for extendido ejemplo aprenderaprogramar.com
public class TestForExtendido {
public static void main (String [] Args) {
ArrayList <String> jugadoresDeBaloncesto = new ArrayList<String> ();
jugadoresDeBaloncesto.add ("Michael Jordan"); jugadoresDeBaloncesto.add ("Kobe Briant");
jugadoresDeBaloncesto.add ("Pau Gasol"); jugadoresDeBaloncesto.add ("Drazen Petrovic");
int i = 0;
System.out.println ("Los jugadores de baloncesto en la lista son: ");
for (String nombre : jugadoresDeBaloncesto) { System.out.println ((i+1) + ".- " +nombre);
i++; }
} //Cierre del main
} //Cierre de la clase
|
Manejo de Excepciones en Java
Este artículo analiza el manejo de excepciones. Una excepción es un error que ocurre en tiempo de ejecución. Utilizando el subsistema de manejo de excepciones de Java, puede, de una manera estructurada y controlada, manejar los errores de tiempo de ejecución.
Aunque la mayoría de los lenguajes de programación modernos ofrecen algún tipo de manejo de excepciones, el soporte de Java es fácil de usar y flexible.
1. Manejo de Excepciones
Una ventaja principal del manejo de excepciones es que automatiza gran parte del código de manejo de errores que previamente debía ingresarse “a mano” en cualquier programa grande. Por ejemplo, en algunos lenguajes de computadora más antiguos, los códigos de error se devuelven cuando falla un método, y estos valores se deben verificar manualmente, cada vez que se llama al método. Este enfoque es tedioso y propenso a errores.
El manejo de excepciones agiliza el manejo de errores al permitir que tu programa defina un bloque de código, llamado manejador de excepción, que se ejecuta automáticamente cuando ocurre un error. No es necesario verificar manualmente el éxito o el fracaso de cada operación específica o llamada a un método. Si se produce un error, será procesado por el manejador de excepciones.
Otra razón por la que el manejo de excepciones es importante es que Java define excepciones estándar para errores comunes del programa, como por ejemplo, dividir por cero o no encontrar el archivo. Para responder a estos errores, tu programa debe vigilar y manejar estas excepciones. Además, la biblioteca API de Java hace un uso extensivo de excepciones.
En el análisis final, ser un programador de Java exitoso significa que usted es completamente capaz de navegar por el subsistema de manejo de excepciones de Java. ¡Empezamos!
2. Jerarquía de excepciones
En Java, todas las excepciones están representadas por clases. Todas las clases de excepción se derivan de una clase llamada Throwable. Por lo tanto, cuando se produce una excepción en un programa, se genera un objeto de algún tipo de clase de excepción.
Hay dos subclases directas de Throwable: Exception y Error:
- Las excepciones de tipo Error están relacionadas con errores que ocurren en la Máquina Virtual de Java y no en tu programa. Este tipo de excepciones escapan a su control y, por lo general, tu programa no se ocupará de ellas. Por lo tanto, este tipo de excepciones no se describen aquí.
- Los errores que resultan de la actividad del programa están representados por subclases de Exception. Por ejemplo, dividir por cero, límite de matriz y errores de archivo caen en esta categoría. En general, tu programa debe manejar excepciones de estos tipos. Una subclase importante de Exception es RuntimeException, que se usa para representar varios tipos comunes de errores en tiempo de ejecución.
3. Fundamentos de manejo de excepciones
El manejo de excepciones Java se gestiona a través de cinco palabras clave: try, catch, throw, throws,
y finally. Forman un subsistema interrelacionado en el que el uso de uno implica el uso de otro. A lo largo de este curso, cada palabra clave se examina en detalle. Sin embargo, es útil desde el principio tener una comprensión general del papel que cada uno desempeña en el manejo de excepciones. En resumen, así es como funcionan.
y finally. Forman un subsistema interrelacionado en el que el uso de uno implica el uso de otro. A lo largo de este curso, cada palabra clave se examina en detalle. Sin embargo, es útil desde el principio tener una comprensión general del papel que cada uno desempeña en el manejo de excepciones. En resumen, así es como funcionan.
Las declaraciones de programa que desea supervisar para excepciones están contenidas dentro de un bloque try. Si se produce una excepción dentro del bloque try, se lanza. Tu código puede atrapar esta excepción usando catch y manejarlo de una manera racional. Las excepciones generadas por el sistema son lanzadas automáticamente por el sistema de tiempo de ejecución de Java. Para lanzar manualmente una excepción, use la palabra clave throw. En algunos casos, una excepción arrojada por un método debe ser especificada como tal por una cláusula throws. Cualquier código que debe ejecutarse al salir de un bloque try se coloca en un bloque finally.
3. Uso de try y catch
En el centro del manejo de excepciones están try y catch. Estas palabras clave trabajan juntas; no puedes atrapar (catch) sin intentarlo (try). Aquí está la forma general de los bloques de manejo de excepciones try/catch:
- try{
- //bloque de código para monitorear errores
- }
- catch (TipoExcepcion1 exOb){
- //Manejador para TipoExepción1
- }
- catch (TipoExcepcion2 exOb){
- //Manejador para TipoExepción2
- }
Aquí, TipoExcepcion es el tipo de excepción que ha ocurrido. Cuando se lanza una excepción, es atrapada por su instrucción catchcorrespondiente, que luego procesa la excepción. Como muestra la forma general, puede haber más de una declaración catch asociada con un try. El tipo de la excepción determina qué declaración de captura se ejecuta. Es decir, si el tipo de excepción especificado por una instrucción catch coincide con el de la excepción, entonces se ejecuta esa instrucción de catch (y todos los demás se anulan). Cuando se detecta una excepción, exOb recibirá su valor.
Si no se lanza una excepción, entonces un bloque try finaliza normalmente, y todas sus declaraciones catch se pasan por alto. La ejecución se reanuda con la primera instrucción después del último catch. Por lo tanto, las declaraciones catch se ejecutan solo si se lanza una excepción.
3.1. Un ejemplo de excepción simple
Aquí hay un ejemplo simple que ilustra cómo observar y atrapar una excepción. Como saben, es un error intentar indexar una matriz más allá de sus límites. Cuando esto ocurre, la JVM lanza una ArrayIndexOutOfBoundsException. El siguiente programa genera a propósito tal excepción y luego la atrapa:
- public class ExcDemo {
- public static void main(String[] args) {
- int nums[]=new int[4];
- try {
- System.out.println("Antes de que se genere la excepción.");
- //generar una excepción de índice fuera de límites
- nums[7]=10;
- }catch (ArrayIndexOutOfBoundsException exc){
- //Capturando la excepción
- System.out.println("Índice fuera de los límites!");
- }
- System.out.println("Después de que se genere la excepción.");
- }
- }
Salida:
Antes de que se genere la excepción. Índice fuera de los límites! Después de que se genere la excepción.
Aunque es bastante breve, el programa anterior ilustra varios puntos clave sobre el manejo de excepciones:
- Primero, el código que desea monitorear para detectar errores está dentro de un bloque try.
- En segundo lugar, cuando se produce una excepción (en este caso, debido al intento de indexar nums más allá de sus límites), la excepción se emite desde el bloque try y es atrapada por la instrucción catch. En este punto, el control pasa al catch, y el bloque tryfinaliza.
- Es decir, no se llama a catch. Por el contrario, la ejecución del programa se transfiere a él. Por lo tanto, la instrucción que sigue a nums[7]=10; nunca se ejecutará.
- Después de que se ejecuta la instrucción catch, el control del programa continúa con las declaraciones que siguen el catch. Por lo tanto, es el trabajo de tu controlador de excepción remediar el problema que causó la excepción para que la ejecución del programa pueda continuar normalmente.
Recuerde, si no se lanza una excepción por un bloque try, no se ejecutarán declaraciones catch y el control del programa se reanudará después de la instrucción catch. Para confirmar esto, en el programa anterior, cambie la línea
nums[7] = 10;
por
nums[0] = 10;
Ahora, no se genera ninguna excepción, y el bloque catch no se ejecuta.
3.2. Un ejemplo de excepción con método
Es importante comprender que todo código dentro de un bloque try se supervisa para detectar excepciones. Esto incluye excepciones que pueden ser generadas por un método llamado desde dentro del bloque try.
Una excepción lanzada por un método llamado desde dentro de un bloque try puede ser atrapada por las declaraciones catch asociadas con ese bloque try, asumiendo, por supuesto, que el método no captó la excepción en sí misma. Por ejemplo, este es un programa válido:
- // Una excepción puede ser generada por un método
- // y atrapada por otro
- public class ExcEjemplo {
- //Generando una exepción
- static void genExcepcion(){
- int nums[]= new int[4];
- System.out.println("Antes de que se genere la excepción.");
- //generar una excepción de índice fuera de límites
- nums[7]=10;
- System.out.println("Esto no se mostrará.");
- }
- }
- public class ExcDemo {
- public static void main(String[] args) {
- int nums[]=new int[4];
- try {
- ExcEjemplo.genExcepcion();
- }catch (ArrayIndexOutOfBoundsException exc){
- //Capturando la excepción
- System.out.println("Índice fuera de los límites!");
- }
- System.out.println("Después de que se genere la excepción.");
- }
- }
Salida:
Antes de que se genere la excepción. Índice fuera de los límites! Después de que se genere la excepción.
Como se llama a genExcepcion() desde un bloque try, la excepción que genera es capturada por catch en main(). Entender, sin embargo, que si genExcepcion() había atrapado la excepción en sí misma, nunca se hubiera pasado a main().
3.3. Captura de excepciones de subclase
Hay un punto importante sobre declaraciones de múltiples catch que se relaciona con subclases. Una cláusula catch para una superclase también coincidirá con cualquiera de sus subclases.
Por ejemplo, dado que la superclase de todas las excepciones es Throwable, para atrapar todas las excepciones posibles, capture Throwable. Si desea capturar excepciones de un tipo de superclase y un tipo de subclase, coloque la subclase primero en la secuencia de catch. Si no lo hace, la captura de la superclase también atrapará todas las clases derivadas. Esta regla se autoejecuta porque poner primero la superclase hace que se cree un código inalcanzable, ya que la cláusula catch de la subclase nunca se puede ejecutar. En Java, el código inalcanzable es un error.
Por ejemplo, considere el siguiente programa:
- // Las subclases deben preceder a las superclases
- // en las declaraciones catch
- public class ExcDemo {
- public static void main(String[] args) {
- //Aquí, num es más grande que denom
- int nums[]={4,8,16,32,64,128,256,512};
- int denom[]={2,0,4,4,0,8};
- for (int i=0;i< nums.length;i++){
- try {
- System.out.println(nums[i]+" / "+
- denom[i]+" es "+nums[i]/denom[i]);;
- }catch (ArrayIndexOutOfBoundsException exc){
- //Capturando la excepción (subclase)
- System.out.println("No se encontró ningún elemento.");
- }
- catch (Throwable exc){
- //Capturando la excepción (superclase)
- System.out.println("Alguna excepción ocurrió.");
- }
- }
- }
- }
Salida:
4 / 2 es 2 Alguna excepción ocurrió. 16 / 4 es 4 32 / 4 es 8 Alguna excepción ocurrió. 128 / 8 es 16 No se encontró ningún elemento. No se encontró ningún elemento.
En este caso, catch (Throwable) detecta todas las excepciones excepto ArrayIndexOutOfBoundsException. El problema de detectar excepciones de subclase se vuelve más importante cuando crea excepciones propias.
4. Los bloques try pueden ser anidados
Un bloque try se puede anidar dentro de otro. Una excepción generada dentro del bloque try interno que no está atrapada por un catchasociado con este try, se propaga al bloque try externo. Por ejemplo, aquí la ArrayIndexOutOfBoundsException no es capturada por el catchinterno, sino por el catch externo:
- // Uso de un bloque try anidado
- public class TryAnidado{
- public static void main(String[] args) {
- //Aquí, num es más grande que denom
- int nums[]={4,8,16,32,64,128,256,512};
- int denom[]={2,0,4,4,0,8};
- try { //try externo
- for (int i = 0; i < nums.length; i++) {
- try { //try anidado
- System.out.println(nums[i] + " / " +
- denom[i] + " es " + nums[i] / denom[i]);
- } catch (ArithmeticException exc) {
- //Capturando la excepción
- System.out.println("No se puede dividir por cero!");
- }
- }
- }
- catch (ArrayIndexOutOfBoundsException exc) {
- //Capturando la excepción
- System.out.println("Alguna excepción ocurrió.");
- System.out.println("ERROR: Programa terminado.");
- }
- }
- }
Salida:
4 / 2 es 2 No se puede dividir por cero! 16 / 4 es 4 32 / 4 es 8 No se puede dividir por cero! 128 / 8 es 16 Alguna excepción ocurrió. ERROR: Programa terminado.
En este ejemplo, una excepción que puede ser manejada por el try interno, en este caso, un error de división por cero, permite que el programa continúe. Sin embargo, un error de límite de matriz es capturado por la try externo, lo que hace que el programa finalice.
Aunque ciertamente no es la única razón para las instrucciones try anidadas, el programa anterior hace un punto importante que se puede generalizar. A menudo, los bloques try anidados se usan para permitir que las diferentes categorías de errores se manejen de diferentes maneras. Algunos tipos de errores son catastróficos y no se pueden solucionar. Algunos son menores y pueden manejarse de inmediato.
Puede utilizar un bloque try externo para detectar los errores más graves, permitiendo que los bloques try internos manejen los menos serios.
5. Lanzar una excepción
Los ejemplos anteriores han estado capturando excepciones generadas automáticamente por la JVM. Sin embargo, es posible lanzar manualmente una excepción utilizando la instrucción throw. Su forma general se muestra aquí:
throw excepcOb;
Aquí, excepcOb debe ser un objeto de una clase de excepción derivada de Throwable. Aquí hay un ejemplo que ilustra la instrucción throwarrojando manualmente una ArithmeticException:
- //Lanzar manualmente una excepción
- public class ThrowDemo {
- public static void main(String[] args) {
- try{
- System.out.println("Antes de lanzar excepción.");
- throw new ArithmeticException(); //Lanzar una excepción
- }catch (ArithmeticException exc){
- //Capturando la excepción
- System.out.println("Excepción capturada.");
- }
- System.out.println("Después del bloque try/catch");
- }
- }
Salida:
Antes de lanzar excepción. Excepción capturada. Después del bloque try/catch
Observe cómo se creó la ArithmeticException utilizando new en la instrucción throw. Recuerde, throw arroja un objeto. Por lo tanto, debe crear un objeto para “lanzar“. Es decir, no puedes simplemente lanzar un tipo.
6. Re-lanzar una excepción:
Una excepción capturada por una declaración catch se puede volver a lanzar para que pueda ser capturada por un catch externo. La razón más probable para volver a lanzar de esta manera es permitir el acceso de múltiples manejadores/controladores a la excepción.
Por ejemplo, quizás un manejador de excepciones maneja un aspecto de una excepción, y un segundo manejador se enfrenta a otro aspecto. Recuerde, cuando vuelve a lanzar una excepción, no se volverá a capturar por la misma declaración catch. Se propagará a la siguiente declaración de catch. El siguiente programa ilustra el relanzamiento de una excepción:
- //Relanzando un excepción
- public class Rethrow {
- public static void genExcepcion() {
- //Aquí, num es más largo que denom
- int nums[] = {4, 8, 16, 32, 64, 128, 256, 512};
- int denom[] = {2, 0, 4, 4, 0, 8};
- for (int i = 0; i < nums.length; i++) {
- try {
- System.out.println(nums[i] + " / " +
- denom[i] + " es " + nums[i] / denom[i]);
- } catch (ArithmeticException exc){
- //Capturando la excepción
- System.out.println("No se puede dividir por cero!.");
- }
- catch (ArrayIndexOutOfBoundsException exc) {
- //Capturando la excepción
- System.out.println("No se encontró ningún elemento.");
- throw exc; //Relanzando la excepción
- }
- }
- }
- }
- public class RethrowDemo {
- public static void main(String[] args) {
- try{
- Rethrow.genExcepcion();
- }
- catch (ArrayIndexOutOfBoundsException exc){
- //Recapturando la excepción
- System.out.println("ERROR - Programa terminado");
- }
- }
- }
Salida:
4 / 2 es 2 No se puede dividir por cero!. 16 / 4 es 4 32 / 4 es 8 No se puede dividir por cero!. 128 / 8 es 16 No se encontró ningún elemento. ERROR - Programa terminado
En este programa, los errores de división por cero se manejan localmente, mediante genExcepcion(), pero se vuelve a generar un error de límite de matriz. En este caso, es capturado por main().
7. Una mirada más cercana a Throwable
Hasta este punto, hemos estado detectando excepciones, pero no hemos estado haciendo nada con el objeto de excepción en sí mismo. Como muestran todos los ejemplos anteriores, una cláusula catch especifica un tipo de excepción y un parámetro. El parámetro recibe el objeto de excepción. Como todas las excepciones son subclases de Throwable, todas las excepciones admiten los métodos definidos por Throwable. Varios de uso común se muestran en la siguiente tabla:
| Método | Sintaxis | Descripción |
|---|---|---|
| getMessage | String getMessage() | Devuelve una descripción de la excepción. |
| getLocalizedMessage | String getLocalizedMessage() | Devuelve una descripción localizada de la excepción. |
| toString | String toString() | Devuelve un objeto String que contiene una descripción completa de la excepción. Este método lo llama println() cuando se imprime un objeto Throwable. |
| printStackTrace() | void printStackTrace() | Muestra el flujo de error estándar. |
| printStackTrace | void printStackTrace(PrintStream s) | Envía la traza de errores a la secuencia especificada. |
| printStackTrace | void printStackTrace(PrintWriter s) | Envía la traza de errores a la secuencia especificada. |
| fillInStackTrace | Throwable fillInStackTrace() | Devuelve un objeto Throwable que contiene un seguimiento de pila completo. Este objeto se puede volver a lanzar. |
De los métodos definidos por Throwable, dos de los más interesantes son printStackTrace() y toString().
- Puede visualizar el mensaje de error estándar más un registro de las llamadas a métodos que conducen a la excepción llamando a printStackTrace().
- Puede usar toString() para recuperar el mensaje de error estándar. El método toString() también se invoca cuando se usa una excepción como argumento para println().
El siguiente programa demuestra estos métodos:
- public class ExcDemo {
- static void genExcepcion(){
- int nums[]=new int[4];
- System.out.println("Antes de lanzar excepción.");
- nums[7]=10;
- System.out.println("Esto no se mostrará.");
- }
- }
- class MetodosThrowable{
- public static void main(String[] args) {
- try{
- ExcDemo.genExcepcion();
- }
- catch (ArrayIndexOutOfBoundsException exc){
- System.out.println("Mensaje estándar: ");
- System.out.println(exc);
- System.out.println("\nTraza de errores: ");
- exc.printStackTrace();
- }
- System.out.println("Después del bloque catch.");
- }
- }
Salida:
Antes de lanzar excepción. Mensaje estándar: java.lang.ArrayIndexOutOfBoundsException: 7 Traza de errores: java.lang.ArrayIndexOutOfBoundsException: 7 at ExcDemo.genExcepcion(ExcDemo.java:8) at MetodosThrowable.main(ExcDemo.java:16) Después del bloque catch.
8. Uso de finally
Algunas veces querrá definir un bloque de código que se ejecutará cuando quede un bloque try/catch. Por ejemplo, una excepción puede causar un error que finaliza el método actual, causando su devolución prematura. Sin embargo, ese método puede haber abierto un archivo o una conexión de red que debe cerrarse.
Tales tipos de circunstancias son comunes en la programación, y Java proporciona una forma conveniente de manejarlos: finally. Para especificar un bloque de código a ejecutar cuando se sale de un bloque try/catch, incluya un bloque finally al final de una secuencia try/catch. Aquí se muestra la forma general de un try/catch que incluye finally.
- try{
- //bloque de código para monitorear errores
- }
- catch(TipoExcepcion1 exOb){
- //manejador para TipoExcepcion1
- }
- catch(TipoExcepcion2 exOb){
- //manejador para TipoExcepcion2
- }
- //...
- finally{
- //código final
- }
El bloque finally se ejecutará siempre que la ejecución abandone un bloque try/catch, sin importar las condiciones que lo causen. Es decir, si el bloque try finaliza normalmente, o debido a una excepción, el último código ejecutado es el definido por finally. El bloque finally también se ejecuta si algún código dentro del bloque try o cualquiera de sus declaraciones catch devuelve del método.
Aquí hay un ejemplo de finally:
- //Uso de finally
- public class UsoFinally {
- public static void genExcepecion(int rec) {
- int t;
- int nums[]=new int[2];
- System.out.println("Recibiendo "+rec);
- try {
- switch (rec){
- case 0:
- t=10 /rec;
- break;
- case 1:
- nums[4]=4; //Genera un error de indexación
- break;
- case 2:
- return; //Retorna desde el blorec try
- }
- }
- catch (ArithmeticException exc){
- //Capturando la excepción
- System.out.println("No se puede dividir por cero!");
- return; //retorna desde catch
- }
- catch (ArrayIndexOutOfBoundsException exc){
- //Capturando la excepción
- System.out.println("Elemento no encontrado");
- }
- finally {
- //esto se ejecuta al salir de los blorecs try/catch
- System.out.println("Saliendo de try.");
- }
- }
- }
Salida:
- class FinallyDemo{
- public static void main(String[] args) {
- for (int i=0;i<3;i++){
- UsoFinally.genExcepecion(i);
- System.out.println();
- }
- }
- }
Como muestra la salida, no importa cómo se salga el bloque try, el bloque finally sí se ejecuta .
9. Uso de throws
En algunos casos, si un método genera una excepción que no maneja, debe declarar esa excepción en una cláusula throws. Aquí está la forma general de un método que incluye una cláusula throws:
- tipo-retorno nombreMetodo(lista-param) throws lista-excepc {
- // Cuerpo
- }
Aquí, lista-excepc es una lista de excepciones separadas por comas que el método podría arrojar fuera de sí mismo.
Quizás se pregunte por qué no necesitó especificar una cláusula throws para algunos de los ejemplos anteriores, que arrojó excepciones fuera de los métodos. La respuesta es que las excepciones que son subclases de Error o RuntimeException no necesitan ser especificadas en una lista de throws. Java simplemente asume que un método puede arrojar uno. Todos los otros tipos de excepciones deben ser declarados. De lo contrario, se produce un error en tiempo de compilación.
En realidad, usted vio un ejemplo de una cláusula throws anteriormente. Como recordará, al realizar la entrada del teclado, necesitaba agregar la cláusula a main(). Ahora puedes entender por qué. Una declaración de entrada podría generar una IOException, y en ese momento, no pudimos manejar esa excepción. Por lo tanto, tal excepción se descartaría de main() y necesitaría especificarse como tal. Ahora que conoce excepciones, puede manejar fácilmente IOException.
9.1. Ejemplo con throws
Veamos un ejemplo que maneja IOException. Crea un método llamado prompt(), que muestra un mensaje de aviso y luego lee un carácter del teclado. Como la entrada se está realizando, puede ocurrir una IOException.
Sin embargo, el método prompt() no maneja IOException. En cambio, usa una cláusula throws, lo que significa que el método de llamada debe manejarlo. En este ejemplo, el método de llamada es main() y trata el error.
- //Uso de throws
- class ThrowsDemo {
- public static char prompt(String args)
- throws java.io.IOException {
- System.out.println(args + " :");
- return (char) System.in.read();
- }
- public static void main (String[]args){
- char ch;
- try {
- //dado que prompt() podría arrojar una excepción,
- // una llamada debe incluirse dentro de un bloque try
- ch = prompt("Ingresar una letra");
- } catch (java.io.IOException exc) {
- System.out.println("Ocurrió una excepción de E/S");
- ch = 'X';
- }
- System.out.println("Usted presionó: " + ch);
- }
- }
En un punto relacionado, observe que IOException está totalmente calificado por su nombre de paquete java.io. Como aprenderá más adelante, el sistema de E/S de Java está contenido en el paquete java.io. Por lo tanto, IOException también está contenido allí. También habría sido posible importar java.io y luego referirme a IOException directamente.
10. Tres características adicionales de excepción
A partir de JDK 7, el mecanismo de manejo de excepciones de Java se ha ampliado con la adición de tres características.
- El primero es compatible con la gestión automática de recursos, que automatiza el proceso de liberación de un recurso, como un archivo, cuando ya no es necesario. Se basa en una forma expandida de try, llamada declaración try-with-resources (try con recursos), y se describe más en Java Avanzado, cuando se discuten los archivos.
- La segunda característica nueva se llama multi-catch.
- Y la tercera a veces se llama final rethrow o more precise rethrow. Estas dos características se describen aquí.
9.1. Característica multi-catch
El multi-catch permite capturar dos o más excepciones mediante la misma cláusula catch. Como aprendió anteriormente, es posible (de hecho, común) que un intento sea seguido por dos o más cláusulas catch. Aunque cada cláusula catch a menudo proporciona su propia secuencia de código única, no es raro tener situaciones en las que dos o más cláusulas catch ejecutan la misma secuencia de código aunque atrapen diferentes excepciones.
En lugar de tener que capturar cada tipo de excepción individualmente, puede usar una única cláusula de catch para manejar las excepciones sin duplicación de código.
Para crear un multi-catch, especifique una lista de excepciones dentro de una sola cláusula catch. Para ello, separe cada tipo de excepción en la lista con el operador OR. Cada parámetro multi-catch es implícitamente final. (Puede especificar explícitamente final, si lo desea, pero no es necesario.) Debido a que cada parámetro multi-catch es implícitamente final, no se le puede asignar un nuevo valor.
Aquí se explica cómo puede usar la función multi-catch para capturar ArithmeticException y ArrayIndexOutOfBoundsException con una única cláusula catch:
catch(ArithmeticException | ArrayIndexOutOfBoundsException e) {
Aquí hay un programa simple que demuestra el uso de multi-catch:
- // Uso de multi-catch
- // Este código requiere JDK7 o superior
- class MultiCatch {
- public static void main(String[] args) {
- int a=28, b=0;
- int resultado;
- char chars[]={'A','B','C'};
- for (int i=0; i<2;i++){
- try {
- if (i==0)
- resultado=a/b; //genera un ArithmeticException
- else
- chars [5]='X'; //genera un ArrayIndexOutOfBoundsException
- }catch (ArithmeticException | ArrayIndexOutOfBoundsException e){
- System.out.println("Excepción capturada: "+e);
- }
- }
- System.out.println("Después del multi-catch");
- }
- }
Salida:
Excepción capturada: java.lang.ArithmeticException: / by zero Excepción capturada: java.lang.ArrayIndexOutOfBoundsException: 5 Después del multi-catch
El programa generará una ArithmeticException cuando se intenta la división por cero. Generará una ArrayIndexOutOfBoundsExceptioncuando se intente acceder fuera de los límites de chars. Ambas excepciones son capturadas por la declaración única de catch.
La función más precisa de rethrow restringe el tipo de excepciones que pueden volver a lanzarse solo a aquellas excepciones marcadas que arroja el bloque try asociado, que no son manejadas por una cláusula catch anterior, y que son un subtipo o supertipo del parámetro. Si bien esta capacidad puede no ser necesaria a menudo, ahora está disponible para su uso.
Para que la característica rethrow esté en vigor, el parámetro catch debe ser efectivamente final. Esto significa que no se le debe asignar un nuevo valor dentro del bloque catch. También se puede especificar explícitamente como final, pero esto no es necesario.
Filtros de Servlet
Los filtros son clases Java que nos permiten interceptar una petición y modificarla antes de que sea procesada por el Servlet, o interceptar una respuesta antes que que la misma sea enviada al cliente, para crear estas clases es necesario implementar la interface
javax.servlet.Filter, la cual define los siguientes tres métodos que debemos implementar:init(FilterConfig cfg). Es invocado por el contenedor una vez que el filtro entra en funcionamiento.destroy(). Este método lo llama el contenedor cuando el filtro de Servlet deja de funcionar.doFilter(ServletRequest req, ServletResponse res, FilterChain chain). El contenedor llama a este método para cada solicitud de Servlet correlacionada con este filtro antes de invocar el Servlet. El Servlet original solicitado se ejecuta cuando el filtro llama al métodochain.doFilter(...).
Diagrama básico de funcionamiento de un filtro.

Para la demostración de nuestro primer filtro usaremos la aplicación creada anteriormente en donde explicábamos como utilizar una plantilla Thymeleaf desde un Servlet, aquella plantilla tiene soporte para internacionalización, más específicamente soporta los idiomas inglés y español, lo que haremos será crear un filtro que nos permita cambiar el idioma usando un parámetro en la URL, por ejemplo:
- Para el inglés: http://localhost:8084/PrimerFiltro/?idioma=en
- Para el español: http://localhost:8084/PrimerFiltro/?idioma=es
El parámetro es idioma con el valor "es" cambiamos a español y con "en" a ingles, esto es lo que tenemos del tutorial antes mencionado.
@WebServlet("/")
public class PrimerServlet extends HttpServlet {
private PrimerThymeleaf primerThymeleaf;
private ServletContext servletContext;
@Override
public void init(ServletConfig config) throws ServletException {
servletContext = config.getServletContext();
primerThymeleaf = new PrimerThymeleaf(servletContext);
}
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8");
response.setHeader("Pragma", "no-cache");
WebContext ctx = new WebContext(request, response, servletContext, response.getLocale());
ctx.setVariable("today", new Date());
TemplateEngine engine = primerThymeleaf.getTemplateEngine();
engine.process("home", ctx, response.getWriter());
}
}
Esta clase responde a la petición HTTP GET procesando la plantilla indicada, lo que nos interesa observar es que al crear el objeto
WebContext le pasamos el objeto Locale que define el idioma, el mismo es obtenido con el método response.getLocale(), el cual obtiene el objeto Locale basada en la cabecera Accept-Language proporcionada por el cliente.WebContext ctx = new WebContext(..., response.getLocale());
Ahora lo que deseamos hacer es cambiar el
Locale por medio de la URL, sin tener la necesidad de cambiar la cabecera Accept-Language en el navegador.Programando Nuestro Filtro
Para este filtro los métodos
init(...) y destroy() no requieren código, pero hay que sobre escribirlos para cumplir con la interface.
Usaremos la anotación
@WebFilter para definir el filtro, debemos indicar la URL con la que trabajara el filtro, para nosotros "/*" nos permite capturar todas las peticiones, esta anotación debe usarse sobre una clase que implemente la interface Filter.@WebFilter("/*")
public class PrimerFiltro implements Filter {
@Override
public void init(FilterConfig config) throws ServletException {
// nada por ahora...
}
@Override
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain)
throws IOException, ServletException {
String idioma = req.getParameter("idioma");
if(idioma != null) {
if(idioma.equals("es") || idioma.equals("en")) {
res.setLocale(new Locale(idioma));
}
}
chain.doFilter(req, res);
}
@Override
public void destroy() {
// nada por ahora...
}
}
Este filtro es bastante sencillo, primero lee el parámetro idioma, si el mismo está presente crea el nuevo objeto
Localey se lo asigna al objeto ServletResponse.String idioma = req.getParameter("idioma");
if(idioma != null) {
if(idioma.equals("es") || idioma.equals("en")) {
res.setLocale(new Locale(idioma));
}
}
Cualquier modificación a la petición, podemos hacerla antes de llamar al Servlet, para pasar el control de la petición al Servlet debemos invocar el siguiente método:
chain.doFilter(req, res);
Si lo deseamos podemos realizar alguna modificación a la respuesta generada por el Servlet antes de pasarla al cliente, esto lo haríamos después de invocar el método
doFileter(...) antes mencionado.
El resultado en el navegador web:


Recordemos que para agregar un parámetro a la URL debemos agregar el símbolo "?" luego de la variable con su valor.
Si bien este filtro es bastante simple y lo que hicimos con él lo pudimos haber hecho desde el propio Servlet, la idea es comprender como un filtro puede interceptar una petición y modificarla antes de pasarla al Servlet o bien modificar la respuesta antes de que esta sea enviada al cliente.
No hay comentarios.:
Publicar un comentario