¿Qué son las páginas web dinámicas?

Las páginas web dinámicas están desbancando a las tradicionales páginas web estáticas. ¿Aún no sabes cuál es la diferencia entre ambos tipos de páginas web? En este artículo te voy a contar las diferencias entre páginas web dinámicas y estáticas, cuáles son las ventajas de las webs dinámicas y cómo puedes tener una web dinámica fácilmente para tu proyecto.
Páginas web dinámicas Vs. Páginas web estáticas
Hasta hace no tanto tiempo, todas las páginas web eran estáticas. Eran páginas en las que se mostraba información de manera permanente. Construidas principalmente con HTML. Su aspecto puede ser muy parecido al de una web dinámica, pero no te dejes engañar. No tienes acceso fácil a actualizar el contenido de la web, necesitas ayuda de la persona que la costruyó para hacer la más mínima alteración del texto, etc. Estas páginas son sumamente simples, no tienen posibilidad de añadirles un blog o otro tipo de aplicaciones para añadirles funcionalidades. No son páginas web que puedan ser mantenidas fácilmente por una persona que no tenga conocimientos de programación.
Hoy en día la mayoría de las nuevas páginas web que se crean son dinámicas. Se construyen usando además otros lenguages de programación como PHP que permiten programar en ellas aplicaciones para todo tipo de funciones: blogs, foros, tiendas, etc. La característica principal es que el contenido es fácilmente y frecuentemente modificado.
Ventajas de las páginas web dinámicas
- Las posibilidades son infinitas. Puedes hacer cualquier cosa que imagines partiendo de una web dinámica. Desde una simple web informativa con los datos de tu empresa o un complejo portal con todo tipo de funciones, un blog, una tienda online, una central de reservas…
- Se posicionan mejor en los buscadores. Como Google a la hora de posicionar una web valora la actualización constante de contenidos, una página web estática siempre tendrá problemas para posicionarse. En cambio una web dinámica es una web viva, la actualización de contenidos puede ser muy frecuente y eso ayuda a posicionarse en los resultados de búsqueda.
- Es mucho más fácil añadir contenidos y modificar cualquier elemento de la web. Lo ideal es tener una web dinámica equipada con un buen gestor de contenidos que te permita añadir páginas, modificar textos o imágenes de una manera eficaz y al alcance de cualquiera. En una página web estática cada pequeño cambio implica modificar todas las páginas de la web y tiene que hacerse mediante ftp y programando, lo cual provoca que el proceso no sea nada ágil y que dependas de profesionales.
- Permiten una mayor interacción con los usuarios, lo cual favorece enormemente la eficacia de la página para atraer clientes.
- Pueden ser mantenidas por personas que no tengan conocimientos de programación.
- Permiten un diseño responsive que se adapta a todo tipo de tamaños de pantalla y dispositivos de navegación: ordenadores, portátiles, tablets, teléfonos móviles, etc.
Por todas estas cosas, las páginas web estáticas son cada vez más una cosa del pasado y han dejado paso a una nueva generación de páginas web interactivas y modernas que han mejorado muchísimo la experiencia de los usuarios en internet.
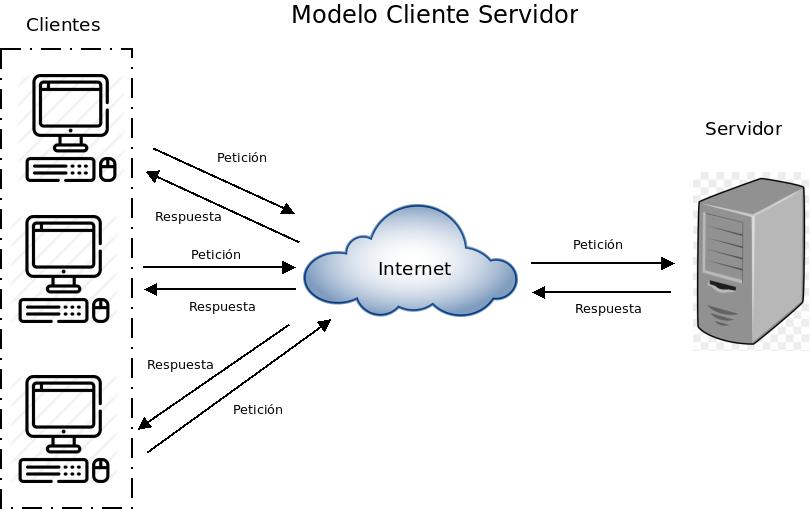
El modelo cliente - servidor
Este modelo es uno de los principales usados en muchísimos servicios y protocolos de Internet, por lo que para todos aquellos que quieren aprender más sobre la web y cómo funciona, entender el concepto de modelo cliente servidor se vuelve algo indispensable.
Importancia del modelo cliente servidor
La arquitectura cliente servidor tiene dos partes claramente diferenciadas, por un lado la parte del servidor y por otro la parte de cliente o grupo de clientes donde lo habitual es que un servidor sea una máquina bastante potente con un hardware y software específico que actúa de depósito de datos y funcione como un sistema gestor de base de datos o aplicaciones.
En esta arquitectura el cliente suele ser estaciones de trabajo que solicitan varios servicios al servidor, mientras que un servidor es una máquina que actúa como depósito de datos y funciona como un sistema gestor de base de datos, este se encarga de dar la respuesta demandada por el cliente.
Esta arquitectura se aplica en diferentes modelos informáticos alrededor del mundo donde su propósito es mantener una comunicaciones de información entre diferentes entidades de una red mediante el uso de protocolos establecidos y el apropiado almacenaje de la misma.
El más claro ejemplo de uso de una arquitectura cliente servidor es la red de Internet donde existen ordenadores de diferentes personas conectadas alrededor del mundo, las cuales se conectan a través de los servidores de su proveedor de Internet por ISP donde son redirigidos a los servidores de las páginas que desean visualizar y de esta manera la información de los servicios requeridos viajan a través de Internet dando respuesta a la solicitud demandada.
La principal importancia de este modelo es que permite conectar a varios clientes a los servicios que provee un servidor y como sabemos hoy en día, la mayoría de las aplicaciones y servicios tienen como gran necesidad que puedan ser consumidos por varios usuarios de forma simultanea.
Componentes
Para entender este modelo vamos a nombrar y definir a continuación algunos conceptos básicos que lo conforman.
- Red: Una red es un conjunto de clientes, servidores y base de datos unidos de una manera física o no física en el que existen protocolos de transmisión de información establecidos.
- Cliente: El concepto de cliente hace referencia a un demandante de servicios, este cliente puede ser un ordenador como también una aplicación de informática, la cual requiere información proveniente de la red para funcionar.
- Servidor: Un servidor hace referencia a un proveedor de servicios, este servidor a su vez puede ser un ordenador o una aplicación informática la cual envía información a los demás agentes de la red.
- Protocolo: Un protocolo es un conjunto de normas o reglas y pasos establecidos de manera clara y concreta sobre el flujo de información en una red estructurada.
- Servicios: Un servicio es un conjunto de información que busca responder las necesidades de un cliente, donde esta información pueden ser mail, música, mensajes simples entre software, videos, etc.
- Base de datos: Son bancos de información ordenada, categorizada y clasificada que forman parte de la red, que son sitios de almacenaje para la utilización de los servidores y también directamente de los clientes.
Diferencia entre cliente y servidor
Como hemos mencionado anteriormente una máquina cliente como servidor se refieren a computadoras que son usadas para diferentes propósitos.
El cliente es un computador pequeño con una estructura al igual a la que tenemos en nuestras oficinas u hogares la cual accede a un servidor o a los servicios del mismo a través de Internet o una red interna. Un claro ejemplo a este caso es la forma en que trabaja una empresa modelo con diferentes computadores donde cada uno de ellos se conectan a un servidor para poder obtener archivos de una base de datos o servicios ya sea correos electrónicos o aplicaciones.
El servidor al igual que el cliente, es una computadora pero con diferencia de que tiene una gran capacidad que le permite almacenar gran cantidad de diversos de archivos, o correr varias aplicaciones en simultaneo para así nosotros los clientes poder acceder los servicios.
En la actualidad existen varios tipos de servidores como hablamos anteriormente. Los mismos pueden contener y ejecutar aplicaciones, sitios web, almacenaje de archivos, diversas bases de datos, entre muchos más.
Es importante mencionar que un cliente también puede tener una función de servidor ya que el mismo puede almacenar datos en su disco duro para luego ser usados en vez de estar conectándose al servidor continuamente por una acción que quizás sea muy sencilla.
Tipos de arquitecturas cliente servidor
Dentro de la arquitectura cliente servidor existen tres tipos en donde hablaremos brevemente de como funciona cada uno de ellos.
Arquitectura de dos capas
Esta se utiliza para describir los sistemas cliente servidor en donde el cliente solicita recursos y el servidor responde directamente a la solicitud con sus propios recursos. Eso significa que el servidor no requiere de una aplicación extra para proporcionar parte del servicio.
Arquitectura de tres capas
En la arquitectura de tres capas existe un nivel intermediario, eso significa que la arquitectura generalmente está compartida por un cliente que como hablamos más arriba es el que solicita los recursos equipado con una interfaz de usuario o mediante un navegador web.
La capa del medio es denominada software intermedio cuya tarea es proporcionar los recursos solicitados pero que requiere de otro servidor para hacerlo. La última capa es el servidor de datos que proporciona al servidor de aplicaciones los datos necesarios para poder procesar y generar el servicio que solicito el cliente en un principio.
Arquitectura N capas
En la arquitectura de tres capas, los servidores dos y tres realizaron una tarea específica por lo tanto un servidor web puede usar los servicios de otros servidores para poder proporcionar su propio servicio.
Por consiguiente la arquitectura en tres niveles es potencialmente una arquitectura en N capasya que así como está contemplado en tres niveles como el caso anterior puede estar compuesto por N servidores donde cada uno de ellos brindan su servicio específico.
Ventajas y Desventajas
Este modelo cliente servidor tiene varias ventajas y desventajas las cuales son importantes mencionar y conocer a la hora de establecer si es lo que estamos necesitando o si se acomoda a lo que estamos buscando.
Ventajas
- Facilita la integración entre diferentes sistemas y comparte información permitiendo por ejemplo que las máquinas ya existentes puedan ser utilizadas mediante una interfaz más amigable para el usuario. De esta manera podemos integrar varias PCs con sistemas medianos y grandes sin necesidad de que todos tengan que utilizar el mismo sistema operativo.
- Al favorecer el uso de las interfaz de gráficas interactivas, los sistemas construidos bajo este esquema tienen una mayor interacción con el usuario.
- La estructura modular facilita de más la integración de nuevas tecnologías y el crecimiento de la infraestructura computacional favoreciendo así la estabilidad de las soluciones.
- El modelo cliente servidor permite además proporcionar a las diferentes áreas de una empresa generar un orden de trabajo en donde cada sector puede trabajar en su área pero accediendo al mismo servidor e información que los demás sin generar conflictos. Esto es de gran utilidad ya que si ponemos como ejemplo una empresa con varios empleados al momento de trabajar es importante que todos puedan hacerlo en simultáneo.
Desventajas
- Requiere habilidad para que un servidor sea reparado. Por ejemplo si un problema ocurre en la red, se requiere de alguien con un amplio de esta para poder repararla en su totalidad para así dejar que la información y el correcto funcionamiento siga su flujo.
- Otro problema es la seguridad, el hecho que se comparte canales de información entre servidores y clientes requieren que estas pasen por procesos de validación, es decir protocolos de seguridad que pueden tener algún tipo de puerta abierta permitiendo que se generen daños físicos, amenazas o ataques de malware.
- Este modelo representa una limitación importante en cuanto a los costos económicos debido a que estos servidores son computadoras de alto nivel con un hardware y software específicos para poder dar un correcto funcionamiento a nuestras aplicaciones. Algo importante a destacar es que no solo es caro a la hora de solucionar problemas como mencionamos antes, sino que también tiene un costo elevado para reemplazar componentes que estén averiados.
Ejemplos de modelo cliente servidor
Existen muchísimos servicios, protocolos y servidores que trabajan con el mismo modelo que mencionamos antes. Casi todo el Internet funciona de esa forma de hecho.
Algunos ejemplos de la arquitectura cliente servidor pueden ser:
- Navegar una web funciona basándonos en un cliente web (navegador) y un servidor webcomo Apache, Nginx o LiteSpeed
- Protocolo FTP, funciona de idéntica forma, se utiliza un cliente de FTP (como Filezilla) para conectar a un servidor FTP (como Pure-FTPD, Proftpd, etc)
- SSH: es idéntico también, se utiliza un cliente SSH para conectar al servidor SSH que corre en una red remota.
- Juegos en red: existen clientes que permiten a jugadores online jugar desde sus casas conectándose a servidores de juegos remotos.
- Sistema DNS: el famoso servidor DNS interactúa con clientes DNS también, es decir, basa su arquitectura en el modelo cliente servidor
- Servidor de Correo: donde clientes de correo consultan el correo al servidor de correoremoto, tanto desde móvil o una computadora de escritorio o laptop.
¿Qué son los servlets?
Los Servlets son módulos escritos en Java que se utilizan en un servidor, que puede ser o no ser servidor web, para extender sus capacidades de respuesta a los clientes al utilizar las potencialidades de Java. Los Servlets son para los servidores lo que los applets para los navegadores, aunque los servlets no tienen una interfaz gráfica.Los servelts pueden ser incluidos en servidores que soporten la API de Servlet (ver servidores). La API no realiza suposiciones sobre el entorno que se utiliza, como tipo de servidor o plataforma, ni del protocolo a utilizar, aunque existe una API especial para HTTP.
Los Servlets son un reemplazo efectivo para los CGI en los servidores que los soporten ya que proporcionan una forma de generar documentos dinámicos utilizando las ventajas de la programación en Java como conexión a alguna base de datos, manejo de peticiones concurrentes, programación distribuida, etc. Por ejemplo, un servlet podría ser responsable de procesar los datos desde un formulario en HTML como registrar la transacción, actualizar una base de datos, contactar algún sistema remoto y retornar un documento dinámico o redirigir a otro servlet u alguna otra cosa.
Ventajas de los Servlets
- Eficiencia. Con CGI tradicional, se arranca un nuevo proceso para cada solicitud HTTP. Si el programa CGI hace una operación relativamente rápida, la sobrecarga del proceso de arrancada puede dominar el tiempo de ejecución. Con los Servlets, la máquina Virtual Java permanece arrancada, y cada petición es manejada por un thread Java de peso ligero, no un pesado proceso del sistema operativo. De forma similar, en CGI tradicional, si hay N peticiones simultáneas para el mismo programa CGI, el código de este problema se cargará N veces en memoria. Sin embargo, con los Servlets, hay N threads pero sólo una copia de la clase Servlet. Los Servelt también tienen más alternativas que los programas normales CGI para optimizaciones como los cachés de cálculos prévios, mantener abiertas las conexiones de bases de datos, etc.
- Conveniencia. Hey, tu ya sabes Java. ¿Por qué aprender Perl? Junto con la conveniencia de poder utilizar un lenguaje familiar, los Servlets tienen una gran infraestructura para análisis automático y decodificación de datos de formularios HTML, leer y seleccionar cabeceras HTTP, manejar cookies, seguimiento de sesiones, y muchas otras utilidades.
- Potencia. Los Servlets Java nos permiten fácilmente hacer muchas cosas que son difíciles o imposibles con CGI normal. Por algo, los servlets pueden hablar directamente con el servidor Web. Esto simplifica las operaciones que se necesitan para buscar imágenes y otros datos almacenados en situaciones estándards. Los Servlets también pueden compartir los datos entre ellos, haciendo las cosas útiles como almacenes de conexiones a bases de datos fáciles de implementar. También pueden mantener información de solicitud en solicitud, simplicando cosas como seguimiento de sesión y el caché de cálculos anteriores.
- Portable. Los Servlets están escritos en Java y siguen un API bien estándarizado. Consecuentemente, los servlets escritos, digamos en el servidor I-Planet Enterprise, se pueden ejecutar sin modificarse en Apache, Microsoft IIS, o WebStar. Los Servlets están soportados directamente o mediante plug-in en la mayoría de los servidores Web.
- Barato. Hay un número de servidores Web gratuitos o muy baratos que son buenos para el uso "personal" o el uso en sites Web de bajo nivel. Sin embargo, con la excepción de Apache, que es gratuito, la mayoría de los servidores Web comerciales son relativamente caros. Una vez que tengamos un servidor Web, no importa el coste del servidor, añadirle soporte para Servlets (si no viene preconfigurado para soportarlos) es gratuito o muy barato.
Características principales de los servlets
- Son independientes del servidor utilizado y de su sistema operativo, lo que quiere decir que a pesar de estar escritos en Java, el servidor puede estar escrito en cualquier lenguaje de programación.
- Los servlets pueden llamar a otros servlets, e incluso a métodos concretos (en la misma máquina o en una máquina remota)
- Los servlets pueden obtener fácilmente información acerca del cliente, tal como su dirección IP, el puerto que se utiliza en la llamada, el método utilizado (GET, POST), etc.
- Permiten además la utilización de cookies y sesiones, unas en el lado del cliente y otras del lado del servidor.
- Pueden actuar como enlace entre el cliente y una o varias bases de datos en arquitecturas cliente-servidor.
- Asimismo, pueden realizar tareas de proxy para un applet.
- Permiten la generación dinámica de código HTML, lo que se puede utilizar para la creación de contadores, banners, etc.
El Ciclo de Vida de un Servlet
Cada servlet tiene el mismo ciclo de vida:

- Un servidor carga e inicializa el servlet.
- El servlet maneja cero o más peticiones de cliente.
- El servidor elimina el servlet.
Inicializar un Servlet
Cuando un servidor carga un servlet, ejecuta el método init del servlet. La inicialización se completa antes de manejar peticiones de clientes y antes de que el servlet sea destruido.Aunque muchos servlets se ejecutan en servidores multi-thread, los servlets no tienen problemas de concurrencia durante su inicialización. El servidor llama sólo una vez al método init al crear la instancia del servlet, y no lo llamará de nuevo a menos que vuelva a recargar el servlet. El servidor no puede recargar un servlet sin primero haber destruido el servlet llamando al método destroy.
Interactuar con Clientes
Después de la inicialización, el servlet puede manejar peticiones de clientes. Estas respuestas son manejadas por la misma instancia del servlet por lo que hay que tener cuidado con acceso a variables compartidas por posibles problemas de sincronización entre requerimientos concurrentes.Destruir un Servlet
Los servlets se ejecutan hasta que el servidor los destruye, por cierre el servidor o bien a petición del administrador del sistema. Cuando un servidor destruye un servlet, ejecuta el método destroy del propio servlet. Este método sólo se ejecuta una vez y puede ser llamado cuando aún queden respuestas en proceso por lo que hay que tener la atención de esperarlas.. El servidor no ejecutará de nuevo el servlet, hasta haberlo cargado e inicializado de nuevo.
GenericServlet
La clase GenericServlet es una clase abstract puesto que su método service() es abstract. Esta clase implementa dos interfaces, de las cuales la más importante es la interface Servlet. La interface Servlet declara los métodos más importantes de cara a la vida de un servlet: init() que se ejecuta sólo al arrancar el servlet; destroy() que se ejecuta cuando va a ser destruido y service() que se ejecutará cada vez que el servlet deba atender una solicitud de servicio. Cualquier clase que derive de GenericServlet deberá definir el método service(). Es muy interesante observar los dos argumentos que recibe este método, correspondientes a las interfaces ServletRequest y ServletResponse. La primera de ellas referencia a un objeto que describe por completo la solicitud de servicio que se le envía al servlet. Si la solicitud de servicio viene de un formulario HTML, por medio de ese objeto se puede acceder a los nombres de los campos y a los valores introducidos por el usuario; puede también obtenerse cierta información sobre el cliente (ordenador y browser). El segundo argumento es un objeto con una referencia de la interface ServletResponse, que constituye el camino mediante el cual el método service() se conecta de nuevo con el cliente y le comunica el resultado de su solicitud. Además, dicho método deberá realizar cuantas operaciones sean necesarias para desempeñar su cometido: escribir y/o leer datos de un fichero, comunicarse con una base de datos, etc. El método service() es realmente el corazón del servlet. En la práctica, salvo para desarrollos muy especializados, todos los servlets deberán construirse a partir de la clase HttpServlet, sub-clase de GenericServlet. La clase HttpServlet ya no es abstract y dispone de una implementación o definición del método service(). Dicha implementación detecta el tipo de servicio o método HTTP que le ha sido solicitado desde el browser y llama al método adecuado de esa misma clase (doPost(), doGet(), etc.). Cuando el programador crea una sub-clase de HttpServlet, por lo general no tiene que redefinir el método service(), sino uno de los métodos más especializados (normalmente doPost()), que tienen los mismos.
argumentos que service(): dos objetos referenciados por las interfaces ServletRequest y
ServletResponse.
En la Figura 9.3 aparecen también algunas otras interfaces, cuyo papel se resume a continuación.
1. La interface ServletContext permite a los servlets acceder a información sobre el entorno en que
se están ejecutando.
2. La interface ServletConfig define métodos que permiten pasar al servlet información sobre sus
parámetros de inicialización.
3. La interface ServletRequest permite al método service() de GenericServlet obtener información
sobre una petición de servicio recibida de un cliente. Algunos de los datos proporcionados por
GenericServlet son los nombres y valores de los parámetros enviados por el formulario HTML y una
input stream.
4. La interface ServletResponse permite al método service() de GenericServlet enviar su respuesta
al cliente que ha solicitado el servicio. Esta interface dispone de métodos para obtener un output
stream o un writer con los que enviar al cliente datos binarios o caracteres, respectivamente.
5. La interface HttpServletRequest deriva de ServletRequest. Esta interface permite a los métodos
service(), doPost(), doGet(), etc. de la clase HttpServlet recibir una petición de servicio HTTP.
Esta interface permite obtener información del header de la petición de servicio HTTP.
6. La interface HttpServletResponse extiende ServletResponse. A través de esta interface los
métodos de HttpServlet envían información a los clientes que les han pedido algún servicio.
El API del JSDK 2.0 dispone de clases e interfaces adicionales, no citadas en este apartado. Algunas de
estas clases e interfaces serán consideradas en apartados posteriores.
public abstract class HttpServlet extends GenericServlet: Es la clase de la cual se debe extender para crear un servlet HTTP. De la clase que extiende obtiene los métodos ya definidos además de los cuales define:
- doGet(HttpServletRequest req, HttpServletResponse resp): Es el método llamado para procesar información que haya sido enviado con el método GET. Este método es llamado concurrentemente para cada cliente por lo que hay que estar atento por posibles variables compartidas que causen problemas.
- doPost(HttpServletRequest req, HttpServletResponse resp): Ídem al anterior pero para el método POST, en general se implementa sólo un método y el otro lo referencia.
Método HTTP GET
El método HTTP GET la requiere información desde el servidor web. Esta información podría ser un archivo, salida de un dispositivo en el servidor, o salida de un programa (tal como un servlet o escritura de un script CGI). Un ejemplo de método HTTP GET corresponde al requerimiento de la página principal de www.mageland.com:
GET / HTTP/1.1 Connection: Keep-Alive User-Agent: Mozilla/4.0 (compatible; MSIE 4.01; Windows NT) Host: www.magelang.com Accept: image/gif, image/x-xbitmap,image/jpeg, image/pjpeg |
En la mayoría de los servidores web, los servlets son accesados vía URLs que comienzan con /servlet/. El siguiente método HTTP GET está solicitando el servlet MyServlet en el servidor www.magelang.com :
GET /servlet/MyServlet?name=Scott&company=MageLang%20Institute HTTP/1.1 Connection: Keep-Alive User-Agent: Mozilla/4.0 (compatible; MSIE 4.01; Windows NT) Host: www.magelang.com Accept: image/gif, image/x-xbitmap,image/jpeg, image/pjpeg |
El URL en este método GET invoca el servlet llamado MyServlet y le pasa dos parámetros, name y compay. Cada parámetro es un par de nombre/valor que sigue el formato nombre=valor. Los parámetros son especificados a continuación del nombre del servlet con un signo de interrogación ('?'), y donde cada parámetro se separa por un signo "&" ('&').
Observe el uso de %20 en el valor del parámetro company. Un espacio señalaría el fin del URL en la línea de la petición del GET, así que debe ser coficado, o substituido por %20. Los desarrolladores de servlets no necesitan preocuparse de esta codificación pues es decodificada automáticamente por la clase HttpServletRequest.
El método HTTP GET tiene una limitación importante. La mayoría de los servidores web limita cuánto datos se pueden pasar como parte del nombre del URL (generalmente algunos cientos bytes.) Si se deben pasar más datos entre el cliente y el servidor, el método del POST del HTTP se debe utilizar en lugar de GET.
Cuando un servidor contesta a una petición HTTP GET, envía un mensaje de respuesta HTTP devuelta. El encabezado de una respuesta HTTP se ve de la siguiente forma:
HTTP/1.1 200 Document follows Date: Tue, 14 Apr 1997 09:25:19 PST Server: JWS/1.1 Last-modified: Mon, 17 Jun 1996 21:53:08 GMT Content-type: text/html Content-length: 4435 <4435 bytes worth of data -- the document body>
|
Método POST
Una petición POST HTTP permite que un cliente envíe datos al servidor. Estos datos se pueden utilizar para varios propósitos, por ejemplo:
- Fijar la información a de un newsgroup.
- Agregar entradas a un libro de visitas de un determinado sitio.
- Pasar más información que lo que una petición GET permite.
El método GET pasa todas sus argumentos como parte del URL. Muchos servidores web tienen un límite de cuánto datos pueden aceptar como parte del URL. El método del POST pasa todos sus parámetros como un flujo de datos de entrada (InputStream), quitando este límite.
Una petición típica del POST puede ser como sigue:
POST /servlet/MyServlet HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE 4.01; Windows NT) Host: www.magelang.com Accept: image/gif, image/x-xbitmap,image/jpeg, image/pjpeg, */ Content-type: application/x-www-form-urlencoded Content-length: 39 name=Scott&company=MageLang%20Institute |
No hay comentarios.:
Publicar un comentario